
Nvidia tesla как использовать
Добавил пользователь Алексей Ф. Обновлено: 05.10.2024
Для чего нужны видеокарты Quadro и Tesla, и почему они такие дорогие?
Наверное, странно видеть в продаже кусок текстолита и кремния за миллион рублей, в то время как игровая видеокарта, которая внутри почти такая же, как Quadro, стоит в 5-10 раз дешевле. Сегодня я расскажу для чего нужны видеокарты Quadro и Tesla, в чем их отличие от игровых видеокарт, а также можно ли на Quadro поиграть в игры.
Профессиональная линейка
Начнем с того, что Quadro, ровно как и Tesla - это профессиональные видеокарты. А чем, собственно, профессиональная видеокарта отличается от НЕпрофессиональной?
Как минимум - ̶ц̶е̶н̶о̶й̶ возлагаемыми задачами. Объясню очень просто: в играх на один кадр приходится относительно немного полигонов, но нужно просчитывать разные эффекты затенения/освещения в режиме реального времени со скоростью в 60 кадров в секунду.
А вот в CAD-программах все совсем иначе. Сцена там, часто, одна, и даже эффекты там есть не всегда, вот только состоит она из огромного количества полигонов (в десятки тысяч раз больше, чем в игровых сценах), которые надо просчитать с большой точностью.
При том в некоторых программах формы объектов описываются математическими функциями (для большей точности), и вот тут-то игровая видеокарта не пойдет ни в какое сравнение с Quadro. При этом у проф. карт есть фишки, которых нет у игровых видеокарт, вроде памяти с ECC.
Для этого и была создана Nvidia Quadro
Эти видеокарты базируются на тех же чипах, что и игровые видеокарты. Например, Quadro RTX 8000 базируется на том же ГП TU102, что и RTX 2080Ti. Даже больше скажу, эти видеокарты много где идентичны, однако различия все же есть.
- Больший объем памяти у Quadro
- Дополнительная гарантия с личным специалистом, к которому можно обратиться в случае возникновения проблем (все эти видеокарты производятся только одни вендором - PNY)
- Сертификация от разработчиков ПО
На последнем хотелось бы остановиться поподробнее. Дело в том, что при использовании профессиональных видеокарт, могут открыться некоторые технологии, которые недоступны при использовании игровых видеокарт той же серии (хотя они их поддерживают).
И вот однажды в какой-то программе ребята запустили недоступную технологию на игровой видеокарте, просто добавив ее в список поддерживаемых в файлах программы. Что за программа не помню, но суть вы уловили.
В общем, Quadro - это видеокарты со специальной сертификацией, которые как-то там оптимизированы под расчеты, но по сути - кроме драйверов и памяти отличий от игровых видеокарт имеют немного. Другое дело - видеокарты Tesla.
А для чего нужны Tesla?
Если просто посмотреть на эти видеокарты, то можно увидеть несколько странностей: видеовыходов нет, система охлаждения - пассивная (несмотря на огромное тепловыделение чипа), а главное - цена. Видеокарты Tesla могут спокойно стоить по миллиону рублей, и для всех это норма.
Но Tesla - не совсем видеокарта, а, скорее, графический ускоритель. То есть сама по себе она не умеет выводить картинку и предназначена для установки в помощь к какой-нибудь другой видеокарте (например, Quadro). Tesla можно обозвать и сопроцессором.
Помимо этого, Tesla имеет больше производительности на операциях двойной точности по сравнению, например, с видеокартой серии GeForce, которую тоже можно использовать как сопроцессор (естественно, сравниваем карты одного поколения). В разы больше памяти на борту у Tesla. Tesla может работать в режиме 24/7, что важно при выполнении длительных научных расчетов.
И там, раз уж на то пошло, целый ворох технологий, которые в рамках этой статьи я не распишу - она превратится в книгу. Так что уясним: Tesla - это вообще по сути не видеокарта, а графический ускоритель, который занимается расчетами и в профессиональных машинах, если и есть Tesla, то работает в тандеме с другой видеокартой.
Хотя есть сервера по каким-нибудь расчетам, так там можно увидеть и по 9-10 Tesla.
А можно ли поиграть на профессиональных видеокартах?
На Tesla это получится, скажем так, с некоторыми затруднениями, тогда как на Quadro - флаг в руки! Однако стоит учесть, что их производительность ниже, чем у игровых аналогов из-за сниженных частот.
Nvidia Tesla - Nvidia Tesla
Nvidia Tesla - это линейка продуктов Nvidia, предназначенных для потоковой обработки или универсальных графических процессоров (GPGPU), названная в честь новаторского инженера-электрика Николы Тесла . Ее продукты начали использовать графические процессоры серии G80 и продолжали сопровождать выпуск новых чипов. Их можно программировать с помощью API CUDA или OpenCL .
Линия продуктов Nvidia Tesla конкурировала с линейками AMD Radeon Instinct и Intel Xeon Phi для глубокого обучения и видеокарт.
Nvidia отказалась от бренда Tesla в мае 2020 года, как сообщается, из-за возможной путаницы с маркой автомобилей . Его новые графические процессоры - это графические процессоры Nvidia Data Center , такие как графические процессоры Ampere A100.
СОДЕРЖАНИЕ
Обзор
Предлагая вычислительную мощность, намного превышающую традиционные микропроцессоры , продукты Tesla нацелены на рынок высокопроизводительных вычислений . По состоянию на 2012 год на базе Nvidia Teslas находятся одни из самых быстрых суперкомпьютеров в мире , в том числе Summit в Национальной лаборатории Ок-Ридж и Tianhe-1A в Тяньцзине , Китай .
Карты Tesla обладают в четыре раза большей производительностью с двойной точностью, чем карты Nvidia GeForce на базе Fermi, с аналогичной производительностью с одинарной точностью. В отличие от потребительских карт Nvidia GeForce и профессиональных карт Nvidia Quadro, карты Tesla изначально не могли выводить изображения на дисплей . Однако последние продукты Tesla C-класса включали один порт Dual-Link DVI.
В рамках проекта Denver Nvidia намерена встраивать процессорные ядра ARMv8 в свои графические процессоры. Это будет 64-битное продолжение 32-битных чипов Tegra .
Приложения
Продукты Tesla в основном используются для моделирования и крупномасштабных вычислений (особенно вычислений с плавающей запятой), а также для создания высококачественных изображений в профессиональных и научных областях.
В 2013 году на оборонную промышленность приходилось менее одной шестой продаж Tesla, но Сумит Гупта прогнозировал увеличение продаж на рынке геопространственной разведки .
NVIDIA Tesla K80 — подробности о самом мощном ускорителе
Вычислительные ускорители NVIDIA Tesla прочно заняли своё место везде, где требуется высокая вычислительная производительность: от биржевого анализа до научных расчётов. Ими комплектуются специальные серверы, на их базе строятся вычислительные суперкластеры. Секрет успеха NVIDIA в этой области — поддержка всех современных как закрытых (CUDA), так и открытых технологий (OpenCL, DirectCompute). И в одной из предыдущих новостей мы уже сообщали, что компания готовит к запуску новые модели ускорителей Tesla, как на базе новой архитектуры Maxwell, так и на основе проверенной временем архитектуры Kepler. Особняком в этом списке стояла модель Tesla K80, которая должна была стать вторым двухпроцессорным вычислительным ускорителем NVIDIA после устаревшего D870.

NVIDIA Tesla K80 не имеет вентилятора

Самый быстрый ускоритель научных расчётов
Не обошлось и без снижения тактовых частот: ядра Tesla K80 работают на частоте всего 562 МГц в базовом режиме и 875 МГц — в турборежиме. Но в данном случае количество бьёт качество: почти 5 тысяч поточных процессоров, а точнее, 4992, работая в турборежиме, легко выдают 2,91 терафлопса вычислительной мощности в режиме двойной точности. В обычном режиме этот показатель снижается до 1,87 терафлопс, что всё равно больше, чем может дать Tesla K40 в турборежиме (1,66 терафлопс). При этом карта имеет стандартную компоновку: один слот PCIe x16 и двойная высота, что незаменимо для компактных систем, от которых, тем не менее, требуется высокая вычислительная мощность. А в режиме одинарной точности вычислений показатели новичка выглядят ещё внушительнее: 8,74 и 5,6 терафлопс соответственно. Быстрая межпроцессорная шина NVLink позволяет избежать традиционных для NUMA-систем «бутылочных горлышек».

Быстрая межпроцессорная шина гарантирует отсутствие узких мест
Не подкачала и подсистема памяти: на борту NVIDIA Tesla K80 установлено сразу 24 гигабайта быстрой памяти GDDR5, что является своеобразным рекордом: даже AMD FirePro W9100 располагает всего 16 гигабайтами. И это честные 24 гигабайта, ведь, в отличие от игровой технологии SLI, данные в памяти первого GPU не должны дублироваться в блоке памяти второго GPU. Надо ли объяснять, что объём памяти в массивных вычислениях играет далеко не последнюю роль? Не забыта и пропускная способность: совокупная производительность подсистемы памяти Tesla K80 достигает 480 Гбайт/с, по 240 Гбайт/с на каждый процессор. Это делает новинку идеальным решением практически для любой сферы, где необходимы массивные вычисления — от астрофизики, генетики и квантовой химии, до анализа больших массивов данных и систем «глубокого машинного обучения». Всего ускорители Tesla могут работать более чем с 280 приложениями и программными пакетами.
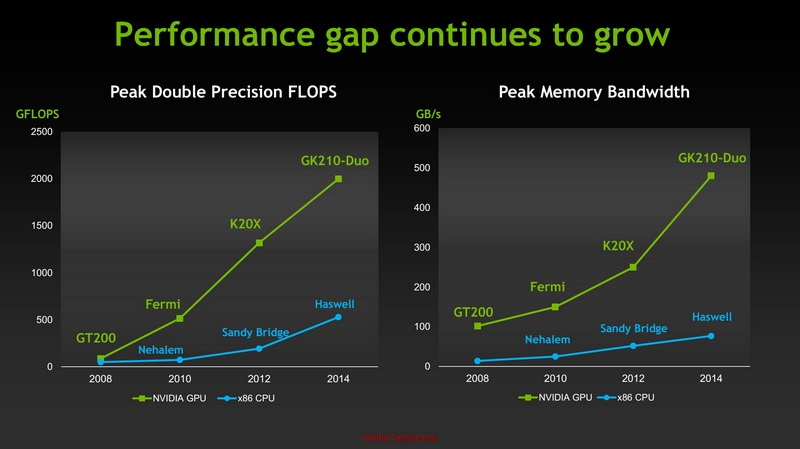
Преимущества GPGPU очевидны

Широкий спектр задач и высокая производительность. У традиционных ЦП нет шансов
В частности, Вольфганг Нейджел (Wolfgang Nagel), директор центра информационных услуг в Дрезденском Техническом Университете, говорит, что учёные используют ресурсы суперкомпьютера Taurus, построенного на базе GPU NVIDIA, для таких задач, как поиск и разработка методов лечения рака, изучения клеток в реальном времени и даже исследования астероидов в рамках прогремевшего недавно на весь мир проекта ESA «Rosetta». А появление новой мощной, но при этом компактной и экономичной модели ускорителя NVIDIA Tesla непременно приведёт к созданию ещё более мощных и эффективных суперкомпьютеров, от чего выиграет и наука, и человечество в целом. Поставки ускорителя NVIDIA Tesla K80 уже начались, подробнее с ним можно ознакомиться в соответствующем разделе веб-сайта NVIDIA, а для скептиков существует даже бесплатная возможность опробовать GPGPU в деле.
А между тем, технологии не стоят на месте, и очень интересно будет взглянуть на будущих монстров Tesla на базе GM200.
Профессиональные видеокарты против игровых — зачем нужна Nvidia Quadro?

Компании Nvidia и AMD выпускают не только геймерские и офисные видеокарты. Та же линейка Nvidia Tesla используется в суперкомпьютерах и мощных вычислительных системах, ориентированных на научные расчеты. А мы поговорим о профессиональных видеокартах для массовых пользователей — линейке Nvidia Quadro и аналогичных.
Зачем нужны профессиональные видеокарты
Все видеокарты выполняют общую задачу — отрисовывают на дисплее кадры, которые до этого подготавливает процессор. Графический чип получает исчерпывающую информацию о сцене: состав и расположение объектов относительно зрителя, цвет, уровень освещения, видимость и так далее. Пару десятилетий назад в играх была пиксельная графика, но сейчас для создания 3D- сцен используются объекты из множества полигонов.
Полигон — это плоскость в трехмерном пространстве. Как правило, в играх используются треугольные полигоны, на основе которых создают уже полноценные 3D-модели. Чем выше число этих треугольников, тем большую детализацию имеет выводимое изображение.

Именно поэтому в старых играх персонажи имеют угловатые формы — вычислительные мощности того времени позволяли оперировать лишь небольшим числом полигонов. По мере совершенствования видеокарт количество полигонов у моделей росло, персонажи становились более реалистичными, резкие углы сглаживались. Это можно хорошо заметить на примере различных ремастеров, например, Crash Bandicoot.

В среднем на одного персонажа приходится от 15 до 45 тысяч таких треугольников. Одним из рекордсменов в этой области является Нейтан Дрейк из Uncharted 4: A Thief's End. В его модели более 80 тысяч полигонов.

А теперь представьте, что на экране несколько персонажей и еще различные объекты окружения. Игровым видеокартам приходится обрабатывать положение пары сотен тысяч полигонов, не говоря о наложении других эффектов.
Если говорить об игровой видеокарте, то ее задача — расположение всех полигонов в пространстве, прорисовка текстур, затенение, создание динамического освещения и сглаживание. В итоге мы видим на экране финальный кадр со всеми эффектами.
Профессиональные видеокарты чаще нужны для САПР, бизнес-приложений, визуализации, инженерных расчетах. Если вы занимаетесь моделированием и работаете в таких программах, как КОМПАС-3D, T-FLEX CAD, SOLIDWORKS, Autodesk 3ds Max и аналогичных, то предпочтительней именно профессиональная видеокарта.
Помимо этого, видеокарты NVIDIA Quadro используются при создании различных спецэффектов в фильмах.
Профессиональная видеокарта делает по сути тоже самое, что и игровая, но с небольшими нюансами. В узкоспециализированных 3D- моделях не нужно накладывать различные эффекты, которые делают графику фотореалистичной. При проектировании и разработке крайне важна точность, поскольку на основе созданных моделей обычно делают реальные вещи. Соответственно, число полигонов может в несколько раз превышать описанные ранее числа — до нескольких миллионов на сцену.
В чем отличия профессиональных и игровых видеокарт
Теперь давайте разберемся, чем конкретно профессиональные видеокарты отличаются от геймерских.
Больший объем видеопамяти. Для обработки огромного числа полигонов нужно много памяти. Для сравнения, видеокарта NVIDIA Quadro P6000 2016 года имеет 24 ГБ памяти. Если взять топовую геймерскую видеокарту на аналогичной архитектуре GTX 1080 Ti начала 2017-го, то у нее всего 11 ГБ памяти. Тенденция сохраняется и с текущим поколением: игровая RTX 3090 оснащается 24 ГБ, в то время ка профессиональная NVIDIA Quadro RTX 8000 имеет целых 48 ГБ.

Жесткая стандартизация. В геймерсих видеокартах существует нереференсные улучшенные модели от сторонних компаний — Asus, MSI, Palit и других. Профессиональные видеокарты выпускаются строго под контролем разработчиков и обычно не имеют нереференсных моделей. Это позволяет исключить ситуации, когда вмешательство вендора привело к неработоспособности устройства.
Использование ECC-памяти. Как мы сказали ранее, в профессиональных видеокартах определяющее значение имеет точность, и ошибки при расчетах недопустимы. В связи с этим используется специальная ECC-память, которая способна распознавать и исправлять спонтанные ошибки в битах. Однако память с коррекцией работает немного медленнее в сравнении с non-ECC, которая стоит на игровых видеокартах. Тесты энтузиастов показывают, что разница скорости между ECC и non-ECC в различных задачах не превышает 2 %.

Аппаратная поддержка OpenGL. Это программный интерфейс, используемый при написании различных приложений с 2D/3D графикой. Аппаратная поддержка ощутимо ускоряет вычисления, но ее реализация повышает стоимость продукта.
Специализированные драйверы и BIOS. Для профессиональной видеокарты нужен специальный драйвер. Он предлагает немного больше настроек, например, в панели Nvidia Control пользователи Quadro могут установить сглаживание граней объектов вплоть до 64Х, в то время как GeForce предлагает только 8X. Также спецдрайвер предоставляет более широкие возможности управления рабочими столами и их конфигурациями.

В установочный пакет драйверов для Quadro входит особое ПО — NVIDIA WMI (Windows Management Instrumentation) и специальный инструмент NVIDIA SMI для мониторинга. Для игровых GeForce GTX/RTX в стандартном пакете этого нет.

BIOS в Quadro разрабатывают непосредственно инженеры компании, а не специалисты сторонних брендов.
Сертификация от разработчиков ПО. В профессиональных моделях крайне важна корректная работа в узкоспециализированных программах без багов и зависаний, поэтому разработчики ПО проводят отдельную сертификацию.
Более длительный жизненный цикл. Обновление линеек геймерских видеокарт происходит в среднем один раз в 1,5-2 года. Профессиональные модели обновляются реже — раз в 2–4 года.
Специфика портов. В профессиональных моделях вы редко встретите HDMI и, тем более, VGA. В Nvidia Quadro последнего поколения используются порты DP1.4, а также Virtuallink. В более старых моделях присутствует DVI порт.

Цена. Рекомендованная цена Quadro RTX 8000 — 9 999 долларов. За топовую геймерскую RTX 3090 придется отдать 1499 доллара, что существенно дешевле.
Профессиональные карты имеют аппаратные и программные особенности, направленные на повышение производительности сугубо в специализированных приложениях для работы с 3D и 2D графикой, а также на общую стабильность и надежность.
Можно ли играть на профессиональных видеокартах?
Технически профессиональные модели имеют все то же, что и игровые: ядра CUDA, блоки растеризации, текстурные блоки, а новые Quadro RTX по аналогии с геймерскими RTX имеют и тензорные ядра. Именно поэтому вы без проблем сможете запустить игру на Quadro или аналогичных с комфортным FPS.
Проблема в том, что Quadro не ориентированы на отрисовку графических эффектов, которые актуальны для видеоигр. Именно поэтому при относительно равных параметрах профессиональные ускорители выдают меньший FPS. На этом сказывается и ориентация драйверов — для Quadro и аналогичных они просто не подогнаны под игры.

Несмотря на то, что профессиональные видеокарты могут показать неплохой результат в играх, с учетом их стоимости покупка будет актуальной только для узкоспециализированных задач.
Nvidia для профессиональных 3D приложений
Пол года назад я искал себе видеокарту, на которой я смог бы заниматься 3d моделированием, и рендерингом на GPU. В связи с появлением на рынке большого числе рендеров на CUDA мне не терпелось приобрести видеокарту с поддержкой CUDA, а именно Nvidia.
Как некоторые уже знают, Nvidia выставляет на продажу видеокарты нескольких моделей Geforce, Quadro, Tesla, ION, Tegra. В этом коротком сравнении упустим ION и Tegra, т.к. предназначены для мобильных устройств и слабые по производительности.
Нам нужна мощь! 
Nvidia power.
ЧТО ГОВОРИТ ПРОИЗВОДИТЕЛЬ
Geforce — видеокарты, ориентированные на потребительский рынок и на геймеров, в частности.
Если вам интересны игры — Geforce лучший вариант для этого.
Видеокарты лучше всего показывают себя в играх, имеют высокие частоты, не дороги, наиболее прожорливы при нагрузке.
В качестве общих вычислительных задач (Cuda, OpenCL) жефорсы упоминаются достаточно редко.
Имеет PhysX, именуемый крутейшим аппаратным решением по ускорению физики. 
Досуг обладателя Geforce (Battlefield 3).
Quadro — видеокарты для пользователей профессиональных приложений 2D и 3D.
Если вы занимаетесь с пакетами 3д моделирования, CAD, сложной векторной графикой — то Вам подойдет Квадра.
Сложные модели на экране рендерятся быстрее, меньше «рывков».
Квадры, сравнимые по производительности с Жефорсами в играх будут в несколько раз дороже.
На картинках сайта nvidia можно увидеть уже больше Куды, чем на жефорсах.
То бишь, видеокарты профессиональные, даже вычислениям общего назначения быть! 
Работа обладателя Quadro (Autodesk Alias Studio).
Tesla — вычислительные системы для научных и технических вычислений общего назначения.
Тут во всю рекламируется CUDA, как крутейший инструмент вычислений общего назначения. Всюду плакаты с аэродинамическими вычислениями, воксельным сканнированием человеческого тела, графические модели нагрузок, и нереально быстрый рендеринг на iRay.
На Tesla отсутствуют видеовыходы, так же как и нету аппаратной растеризации: не работает ни OpenGL, ни DirectX. 
Работа обладателя Quadro + Tesla (Quadro — 3d графика, Tesla — молекулярная динамика).
***
НЕБОЛЬШОЕ ИССЛЕДОВАНИЕ
Когда начал разбираться в их различии, был удивлен тем фактом, что видеокарты GeForce, Quadro, Tesla используют одинаковые графические чипы.
Рассмотрим видеокарты с одинаковым, уже не самым новым, чипом GF100 имеет (512 CUDA ядер):
Одночиповые:
GeForce: GTX465, GTX470, GTX480
Quadro: 4000, 5000, 6000
Tesla: C2050, C2070, M2050, M2090
Рассмотрим по одному представителю с каждого семейства поподробнее.
GeForce GTX480
Некогда топовая игровая видеокарта.
Стоимость: на момент выпуска около 500$ (сейчас бу и за 300 видел), на данный момент не выпускается (на смену пришли GTX580 512 ядер, и GTX680 1536 ядер)
Количество ядер CUDA — 480.
Объем памяти 1.5 Gb.
Производительность float:
Одинарная точность: 1344,9 Гфлопс.
Двойная точность: 168,1 Гфлопс.
(Существует более урезанная версия GTX470, сейчас можно найти по цене меньше 250$, 448 ядер CUDA, 1.25 Gb)
Quadro 5000
Одна из лучших видеокарт для профессиональных приложений.
Стоимость: по данными Amazon около 1700$. Выпускается.
Количество ядер CUDA — 352.
Объем памяти 2.5 Gb.
Производительность float:
Одинарная точность: 718.08 Гфлопс.
Двойная точность: 359.04 Гфлопс.
(Стоит обратить внимание на Quadro 6000, 448 ядер, 515 Гфлопс двойной точности, 4000$)
Tesla C2075
Стоимость: по данными Amazon около 2200$. Тоже выпускается.
Количество ядер CUDA — 352.
Объем памяти 6 Gb.
Производительность float:
Одинарная точность: 1030 Гфлопс.
Двойная точность: 515 Гфлопс.
Что мы видим?
Заметим, что по float производительности выигрывает GeForce GTX480. Причиной тому самое большое количество рабочих ядер и самые высокие частоты среди аналогов. Это нужно для преобразования координат объектов в играх, расчета теней, расчета пиксельных и вершинных шейдеров. В конечном итоге — чтобы игра «летала».
Но, чтобы для научных исследований, моделирования динамики жидкостей и газов покупали Теслы и Квадры — в двойной точности производительность сильно урезана, и уступает аналогам.
Соотношение производительности:
GeForce: double/float — 1/8
Quadro и Tesla: double/float — 1/2
Кроме того, самым малым объемом памяти обладает тот же GTX480. Для игр достаточно, но если хотите провести расчет аэродинамики — покупайте что-то посерьезнее.
***
ЧЕГО НУЖНО?
(Людям, занимающимся 3d графикой)
1. Поменьше тормозов во время редактирования 3d модели.
2. Некоторых интересует возможность быстрого рендеринга на GPU.
3D производительность GeForce vs Quadro
Из информации изложенной выше может показаться, что профессиональными приложениями на GeForce не пользуются из-за того, что имеет малый объем памяти, но это не так.
Ролик покажет Вам, почему «плохая Квадра» лучше «хорошего Жефорса» в профессиональных приложениях.
Quadro 600: 1Gb, 96 ядер CUDA, 150у.е.
GTX560Ti: 1Gb, 384 ядра CUDA, 250у.е. (Цены взяты из Amazon)
Выходит, Nvidia тщательно следит, чтобы 3d производительность в профессиональных приложениях Geforce уступали Quadro при соизмеримых ценах.
Как могут быть реализованны тормоза во вьюпорте?
Дело в том, что количество полигонов в играх существенно меньше, чем у профессионалов в профессиональных приложениях. В играх редко доходит до одного млн полигонов, а в профессиональных — десятки миллионов.
Тут можно сделать так: урезать производительность при преобразовании координат вершин. Если вершин больше определенного количества — то поставить задержку перед отрисовкой последующих вершин.
Либо установить задержку при отрисовке треугольников. Если больше определенного количества — то поставить задержку перед отрисовкой каждого последующего треугольника.
Маленькое лирическое отступление, или Nitrous в 3ds Max.
Меня ввел в заблуждение Nitrous движок в 3ds Max, который стоит рядом с OpenGL и DirectX. Это как? В Autodesk есть что-то, что вызывает Нитрос, аппаратная поддержка которого, оказывается, есть на каждой уважающей себя видеокарте, но знает о ней только 3Д Макс? 
Ну, можно составить небольшую логическую цепочку. Autodesk является богатой корпорацией, и в хороших партнерских отношениях с производителями ATI и Nvidia. Повышать нужно продажи своего детища же! А как бы заинтересовать потребителей? Производительностью же!
Итак, GeForce GTX580 (да, купил я именно её), 7.3 млн треугольников, 2560 Torus Knot-ов, без теней и без Adaptive degradation. 
Nitrous — 42 fps; Direct3d — 13 fps; OpenGL — 2 fps.
OpenGL — тормозит. DirectX — намного лучше. А Nitrous — круче всех, оказывается! Что же нитрос тогда?
Два варианта:
1. Это OpenGL/DX в котором убраны дополнительные тормоза во вьюпорте, созданные умышленно в OpenGL/DX режимах.
2. Это OpenGL/DX, который умеет обращаться к аппаратным функциям игровых видеокарт, и проявлять в них квадровые способности!
И я склонен именно к 2 варианту, т.к. в Blender и в Rhino3D это же самое дико тормозит (2fps).
Выходит, пользователям 3ds Max и других продуктов Autodesk вовсе не так принципиально переходить на Квадру? К сожалению, у меня нету Квадры, чтобы проверить производительность Нитроса по сравнению с OpenGL.
Если же у Вас GeForce или Radeon, нет желания раскошелиться за Квадру, вы Не пользуетесь продуктами от Autodesk, и у Вас очень сложные модели, то:
1. Сложные объекты можно скрыть. Объекты можно показывать во вьюпорте с меньшей плотностью сетки.
2. Вместо объектов можно показывать «контейнеры», их содержащие.
То есть следить за количеством полигонов в вьюпорте, если у вас действительно «тяжелые» модели.
Зато в игры нормально поиграете.
GPU рендеринг
Поскольку коммерческие производители не рассказывают о том, какие типы данных (float или double) они используют — приходится только догадываться.
iRay везде показывают с Quadro и Tesla, может создаться впечатление, что iRay вообще не работает с GeForce. 
Картинка с оф. сайта nvidia.
Но нет, работает, и еще как. Казалось бы, что может быть лучше для не-графических вычислений, чем видеокарта Tesla, специально заточенная под не-графические вычисления? 
(Взято с поста: «V-Ray и Iray. Сравнение и обзор»)
GeForce GTX580 является самой быстрой одночиповой видеокартой в iRay рендеринге на GPU. И значительно дешевле «серьезных» аналогов такой же производительности. А если вам не хватает 1.5Гб, существуют GTX580 с 3Гб памяти.
При использовании V-RayRT, Octane, Cycles, Arion также лучше всех себя показывают видеокарты GTX570 и 580. Выходит, все эти рендеры не используют расчет двойной точности для рендеринга?
В любом случае, если вы хотите рендерить на GPU — на GeForce вы сможете хорошо сэкономить.
GTX680
Но корпорация заметила, что для вычислений все чаще начали брать GTX580, производительность double в GTX680 уступает float не в 8 раз, а в 24, что не могло не отразиться на некоторых тестах.
Известно, что в Octane Render производительность возросла на 64%.
ATI Radeon vs FirePro
Аналогично Nvidia, корпорация AMD тоже разделила модели видеокарт. Radeon (аналог GeForce), FirePro (аналог Quadro), FireStream (аналог Tesla). Производительность вычислений с плавающей точкой двойной точности уступает одинарной в 4 раза, во всех моделях ATI. Интересно, что производительность топовых игровых видеокарт ATI (Radeon HD 7970, float — 3.79 Тфлопс, double — 947 Гфлопс) превосходит в двойной точности даже одночиповые Tesla. Надо заметить, что производительность в флопсах, не всегда является показателем производительности железа в конкретных случаях.
Причина, по которой ATI сильно уступает Nvidia на рынке GPGPU мне пока не ясна. Может, игрового сегмента вполне хватает.
Выбор?
Я выбрал GTX580 3Gb. Видеокарта дает возможность насладиться новыми играми и производительностью GPU рендеров. А тормоза во вьюпорте пакетов 3d моделирования для меня не сильно критичны.
Автор статьи с уважением относится к этому производителю, и сам является счастливым обладателем карточки Nvidia.
Подобные маркетинговые ходы являются неотъемлемой частью рыночной экономики, к ним прибегают все производители без исключения.
Но все же, не будем же вестись на маркетинговые уловки корпораций, а вдумчиво покупать то, что действительно полезно для нас!
Вычислительные системы NVIDIA Tesla

Графические процессоры NVIDIA® Tesla™ — основа построения рабочих станций Team Workstation, выполняющих роль суперкомпьютеров. Их использование позволяет существенно увеличить производительность решения вычислительных задач в различных областях, включая обработку видео и изображений, биологию и химию, моделирование динамики жидкостей, сейсмических исследованиях и многих других. С подробным перечнем приложений, ориентированных на использование TESLA можно ознакомиться на сайте NVIDIA.
Вычисления с GPU-ускорением обладают беспрецедентной производительностью благодаря тому, что части приложения, требующие большой вычислительной мощности, обрабатываются специализированным графическим процессором. При этом остальная часть приложения выполняется на CPU.
В отличие от CPU, состоящего из нескольких ядер, оптимизированных для последовательной обработки данных. GPU состоит из тысяч более мелких и энергоэффективных ядер, созданных для обработки нескольких задач одновременно.
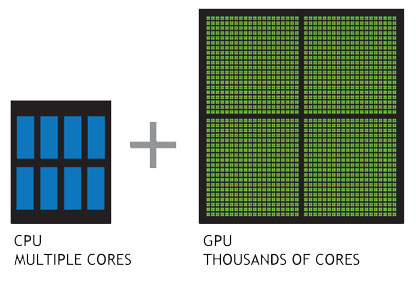
Вычислительная система на NVIDIA TESLA является ведущей платформой для ускорения научных вычислений и анализа больших данных. Она объединяет в себе самые быстрые графические ускорители, широко распространенную модель параллельных вычислений CUDA от NVIDIA и обширную экосистему разработчиков программного обеспечения.
Технология NVIDIA мульти-GPU позволяет успешно масштабировать производительность за счет использования в одной системе комбинации из нескольких графических карт NVIDIA TESLA или NVIDIA QUADRO.
Несколько цифр для иллюстрации. Графический ускоритель Tesla K80 обеспечивает производительность в операциях двойной точности дот 2,91 терафлопс, а производительность в операциях с одинарной точностью до 8,74 терафлопс.
Высокая производительность обработки крупных наборов данных достигается благодаря большому объему встроенной памяти (24 ГБ памяти на Tesla K80 GPU). Увеличенная скорость передачи данных для обеспечения их доступности обеспечивается высокой пропускной способностью используемой памяти (480 Гбит/с для Tesla K80 GPU).
Ниже приведена гистограмма сравнения производительности процессоров GPU и CPU.
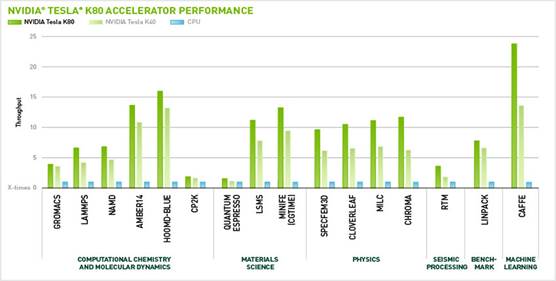
Графический ускоритель NVIDIA TESLA K20 оснащен одним процессором Kepler GK110, 12 ГБ памяти и обеспечивает пиковую производительность вычислений с двойной точностью в 1,17 терафлопс.
Графический ускоритель NVIDIA TESLA K40 оснащен одним процессором Kepler GK110B, 12 ГБ памяти и обеспечивает пиковую производительность вычислений с двойной точностью в 1,43 терафлопс.
Графический ускоритель NVIDIA TESLA K80 - новинка с двумя GPU Kepler GK210 и 24 ГБ памяти с пропускной способностью 480 Гбит/с . Благодаря технологии NVIDIA GPU Boost™ пиковая производительность вычислений двойной точности с плавающей запятой достигает 2,7 терафлопс.
NVIDIA Tesla M10 для GRID выводит виртуализацию настольных ПК с ускорением на GPU
NVIDIA представила новую опцию видеокарты для своей платформы виртуальных рабочих столов GRID. Это Tesla M10, и он призван сделать бизнес более доступным для предоставления виртуальных рабочих столов всем своим сотрудникам по модели подписки, которая начинается всего за 2 доллара на пользователя в месяц (при подписке с трехлетним планом).
Суть NVIDIA в том, что бизнес-приложения вышли за рамки простых документов и электронных таблиц, где 2D-ускорение было достаточным. Современные приложения, включая Outlook, Office 2016, веб-браузеры, Adobe Photoshop и даже Windows 10, могут воспользоваться преимуществами ускорения графического процессора. Эта тенденция не изменится, и именно здесь в игру вступает Tesla M10.

NVIDIA заявляет, что Tesla M10 предлагает самую высокую плотность пользователей в отрасли. В частности, он поддерживает 64 рабочих места на плату и 128 рабочих мест на сервер, что позволяет предприятиям экономически эффективно развертывать виртуализированные рабочие места для всех своих сотрудников, не требуя от бухгалтерии выяснить, как платить за все это.


NVIDIA отмечает, что GRID является отраслевым стандартом для графической виртуализации, поддерживается всеми корпоративными OEM-производителями и обеспечивает полную совместимость с любым приложением для ПК. Новое программное обеспечение GRID доступно уже сейчас, а опция Tesla M10 GPU появится в августе.
Как прикупить Nvidia Tesla за не дорого?
Сам модуль в ближайшей округе стоит в районе 85 килорублей, но когда пытаюсь посмотреть готовое решение, то выползают цены за 200 килорублей.
В идеале нужен стоечный корпус с теслой без особых наворотов (место особо не проблема) — можно ли уложиться в 120-130 килорублей?
Топик будет там работать без вариантов. Безусловно, если пойму окончательно зачем всё это нужно.
Update Отбой: видимо не судьба
А сколько модулей надо? А то сам стоечный корпус можно и своими силами сделать. Опытное производство есть же?
Если это и нужно, то нужен один модуль исключительно для тестов.
Делать на опытном производстве производстве гораздо дороже (не говоря уж про дольше), чем купить готовый.


У меня на работе есть две C1060, которые сейчас уже не подходят для наших задач. Возможно, начальство согласится их продать, ибо всё равно они без дела валяются. Если интересно, можешь связаться со мной, у меня в профиле мыло указано.
На тесле ядер гораздо больше, чем на geforce, соответственно, расчёты на ней тоже выполняются на порядок быстрее. Ещё мне тут рассказывали люди, которые как раз занимаются программированием gpu, что под оффтопиком multigpu с geforce не работает, нужно перепрошивать саму карточку; с теслой и онтопиком таких проблем нет.
Имелись в виду теслы, конечно же.
Спасибо, но вряд ли пройдёт. Если покупка и будет, то только за грантовские деньги.
Про кеплер не скажу, но на чипе ферми теслы по количеству ядер точно соответствовали верхним джифорсам, а по частоте еще и процентов 10 им проигрывали. Ширина канала памяти тоже не выдающаяся. Единственная разница была в числе дабл-устройств, на даблах и была разница в производительности. Насчет multigpu я точно не отвечу, не пробовал, но на той машине точно были венды и две карты независимо работали.
Для наших вычислений скорость на double является определяющей.
Ок, не буду спорить, но такие вещи лучше проверять практически. На гпу можно упереться и раньше, например в недостаток параллелизма или ширину канала памяти. Так за те 200 килорублей дают отдельную карту или машину в сборе? Для карты больно большая накрутка.
Я на самом деле как раз и думаю, что в моей области (физика высоких энергий) GPU не применимо в принципе и Tesla нужна как раз для проверки этой идеи :)
85 кр сама карта, а сборки даже для десктопа начинаются с 200 кр. Стоечные решения стоят гораздо дороже, но за счёт нескольких устройств в одном корпусе (обычно 4 для 4U)

Для наших вычислений скорость на double является определяющей.
Кхм, а зачем вам тогда nVidia? Тыц.
Все дело в памяти и наличие у этой памяти ecc. У тесел ее может быть до 6 гигов. И потом если мне память не изменяет на джифорсах нет возможности доступа к памяти другого устройства через infiniband
А на попробовать действительно прще взять какой-нибудь из джифоросов. Сразу станут ясны тонкие места и во что упираемся.

85 штук, это примерно та цена, за которую её предлагают в Новосибирске.
В geforce намеренно покромсали вычисления, чтобы подхлестнуть спрос на теслы и квадро. Геймерам оно всё равно ни к чему.
Я понимаю, но зачем покупать за 85, когда можно купить за 35?
А что эта самая сандра мерит. Линпак там, матрицы да fft всякие это да.
Потому что ФЗ-93
Evgueni> Я на самом деле как раз и думаю, что в моей области (физика высоких энергий) GPU не применимо в принципе и Tesla нужна как раз для проверки этой идеи :)
GPU (оно же Tesla) в этой области применимо постольку, поскольку нужные аппаратные функции присутствуют. Имеет куда больший смысл прибиться к какому-нибудь готовому мощному кластеру.

RussianNeuroMancer> Кхм, а зачем вам тогда nVidia? Тыц.
Судя по его манере обращения - к нему поступило указание от начальства взять именно нвидию. А то, что обычные радеоны мощнее, чем даже Tesla - ни для кого не секрет. Если лично тебе интересно - могу дать статейку с графическим материалом на эту тему.
Turbo_Mascal> В geforce намеренно покромсали вычисления, чтобы подхлестнуть спрос на теслы и квадро. Геймерам оно всё равно ни к чему.
А ничего, что тесла всё равно отстаёт от игрового гадеона?
Попахивает протекционизмом. Нужно сообщить в WTO.
Еще нужно заставить Рога и Копыта участвовать во всем этом спектакле. И таки да не стоит забывать про проблемы с гарантией.
В этом тесте Тесла использует OpenCL, производительность которого не приоритетна для нвидии.
А что эта самая сандра мерит. Линпак там, матрицы да fft всякие это да.
Тоже не в курсе печальной истории GK104, да? Там даблы порезаны by design, от тестов это не зависит.
Ну и в топку тогда нвидию за такое отношение к клиентам. Radeon оказался быстрее на __стандартной__ технологии.
Десять процентов с этих пяти тысяч - 500 рублей с верху плюс оплата работы брокера. Всё равно это не 85 тысяч, и даже не 40.
6-core CPU (using all cores) by a decisive margin. The fastest loop time was observed for an AMD Radeon HD 6970 (Cayman XT), followed by the Tesla C2070 (Fermi) and the AMD/ATI FirePro V8800 (Cypress) posting nearly identical times that were only marginally slower. The Tesla C2070 is unique in providing support for ECC memory, which is critical in many HPC environments. With ECC memory enabled, the C2070 exhibits only a slight performance penalty, and still decisively outperforms the CPU.
Таки жаль, что нет кода на куде и нет сравнения с интеловскими процами и их opencl реализацией.
А тьфу, забыл, там не десять процентов, а тридцать нужно платить при стоимости товара свыше 30 тысяч.
Я в курсе. Я спрашивал, что мерит сандра ? Мне интересна например скорость перемножения матриц. Кому то интересен fft. А то что радеоны хорошо биткоины генерят это известно.
s/93/94/ и к счастью к грантовским деньгам это не имеет никакого касательства, но за все покупки нужно отчитываться достаточно подробно.
А тьфу, забыл, там не десять процентов, а тридцать нужно платить при стоимости товара свыше 30 тысяч.
И ты ещё забыл, что импорт для юрлиц - это не получение посылки с ибея в ближайшем отделении почты. Там геморрой совершенно другого уровня 8).
The SiSoftware OpenCL Benchmarks look at the two major performance aspects:
Computational performance: in simple terms how fast it can crunch numbers. It follows the same style as the CPU Multi-Media benchmark using fractal generation as its workload. This allows the user to see the power of the GPGPU in solving a workload thus far exclusively performed on a CPU.
Memory performance: this analyses how fast data can be transferred to and from the GPGPU. No matter how fast the processing, ultimately the end result will be affected by memory performance.
Это давно появилось ? А то я помню, что и деньги по грантам нужно тратить через аукционы.
Здесь две проблемы:
а) Обеспечение настоящих потребностей aka обработка данных с установок имеющих скромную светимость. Здесь уже прибились к кластеру НГУ и скоро прибьёмся к кластеру ССКЦ, а в будущем и к Томску. Причём диверсификация нужна исключительно по причине того, что время от времени кластер НГУ по той или иной причине отключается, а нам важна пиковая мощность и возможность поставить задания вообще, а не интеграл.
б) Обеспечение (если марсиане прилетят и профинансируют) потребностей проекта Супер-чарм-тау-фабрики. Тут прибиться не получится, потому-что объём данных за сотни петабайт, так что придётся городить свою инфраструктура и прежде чем городить нужно знать что именно городить.
GPU для наших целей не особо применимо, так как для обработки одного события с детектора или для его моделирования требуется много памяти и внутри одного события параллелить вряд-ли удастся (особенно в случае моделирования). В принципе наверное GPU применимы для предварительной обработки одной из систем для поиска Черенковских колец в реальном времени, но это единственное, что мне приходит в голову.
В этом году вроде как послабление.
У меня бюджетная организация и такие вещи прямо запрещены законом. В частности из-за подобных выкрутасов с контролем всех мелочей, то что я хочу купить на деньги гранта (если удастся это протолкнуть), не покупается уже свыше года (отдел планирования и отдел снабжения увеличились в разы, а закупки вообще встали — спасибо ФЗ94).
Начальство ничего мне не указывало. Начальству как бы параллельно в этом конкретном случае. А по поводу GPU мне статьи интересны. В частности я прошу дать мне ссылки на них вот тут: Использование GPU для высокопроизводительных вычислений
Таможня у нас в Новосибирске обойдётся
10000 за один код, если оформлять через таможенного брокера, на сколько я понимаю.
Ну а то я незнаю. Я сам работаю в академическом институте. И мне эта тема хорошо знакома. Просто все зависит от отдела закупок. Если он идет навстречу, то возможны разные варианты.
Нет. К примеру, для товара стоимостью 35 тысяч сбор будет составлять 1500р, т.е. 30% от 5 тысяч. Не ручаюсь за 100% достоверность, также могло что-то измениться.
Nvidia Tesla
GPU NVIDIA Tesla – это массивно параллельные ускорители, основанные на платформе параллельных вычислений NVIDIA CUDA. Графические процессоры Tesla специально разработаны для экономичных, высокопроизводительных вычислений, вычислительной науки и супервычислений, обеспечивая намного более высокую скорость работы широкого круга научных и коммерческих приложений по сравнению с системой на базе CPU.
CUDA – это платформа параллельных вычислений и модель программирования NVIDIA, которая обеспечивает значительное ускорение ресурсоемких расчетов с помощью графических процессоров. Модель программирования CUDA, загруженная более 1,7 миллиона раз и поддерживающая свыше 220 ведущих инженерных, научных и коммерческих приложений, является самым распространенным способом использования GPU ускорения при разработке приложений.
2017: Nvidia Tesla V100
GPU для дата-центров, предназначенный для ускорения искусственного интеллекта, HPC и графики. Основанный на самой современной архитектуре GPU [Nvidia Volta]], Tesla V100 предлагает в одном GPU производительность, равную 100 CPU, предоставляя ученым, исследователям и инженерам возможность находить решения для ранее нерешаемых проблем.
Тренировка алгоритмов искусственного интеллекта
Ученые берутся за все более сложные задачи, начиная от распознавания речи и обучения виртуальных ассистентов и заканчивая обнаружением дорожной разметки, и обучением беспилотных автомобилей вождению. Решение подобного рода задач требует обучения экспоненциально более сложных моделей нейронных сетей в сжатые сроки.
Оснащенный 43 тыс. ядер Tensor, Tesla V100 – это первый ускоритель, преодолевший барьер производительности в 100 тера-операций в секунду (TOPS) в задачах глубокого обучения. Второе поколение технологии NVIDIA NVLink™ соединяет несколько графических ускорителей V100, обеспечивая пропускную способность в 160 ГБ/с и позволяя создавать самые мощные вычислительные серверы. Модели, обучение которых занимало недели на системах предыдущего поколения, теперь можно натренировать всего за несколько дней. Благодаря такому серьезному сокращению времени, затрачиваемого на тренировку алгоритмов, искусственный интеллект поможет решить самовершенно новые проблемы.
Чтобы открыть нам доступ к актуальной информации, сервисам и продуктам, компании начали использовать искусственный интеллект. Однако удовлетворение потребностей пользователей – сложная задача. К примеру, по оценкам крупнейших компаний с гипермасштабируемой инфраструктурой, им придется вдвое увеличить быстродействие своих дата-центров, если каждый пользователь будет пользоваться их сервисами распознавания речи всего по три минуты в день.
Ускоритель Tesla V100 создан для обеспечения максимальной производительности в существующих сверхмасштабируемых дата-центрах. Один сервер, оснащенный Tesla V100 GPU и потребляющий 13 кВт энергии, обеспечивает в задачах инференса такую же производительность, как 30 CPU-серверов. Подобный скачок производительности и энергоэффективности способствует расширению масштабов применения сервисов с искусственным интеллектом.
высокопроизводительные вычисления
HPC – фундаментальная опора современной науки. Начиная от прогнозирования погоды и создания новых лекарств и заканчивая поиском источников энергии, ученые постоянно используют большие вычислительные системы для моделирования нашего мира и прогнозирования событий в нем. Искусственный интеллект расширяет возможности HPC, позволяя ученым анализировать большие объемы данных и добывая полезную информацию там, где одни симуляции не могут предоставить полную картину происходящего.
Графический ускоритель Tesla V100 создан, чтобы обеспечить слияние HPC и искусственного интеллекта. Это решение для HPC-систем, которое отлично проявит себя как в вычислениях для проведения симуляций, так и обработке данных для извечения из них полезной информации. Благодаря объединению в одной архитектуре ядер CUDA и Tensor, сервер, оснащенный графическими ускорителями Tesla V100, может заменить сотни традиционных CPU-серверов, выполняя традиционные задачи HPC и искусственного интеллекта. Теперь каждый ученый может позволить себе суперкомпьютер, который поможет в решении самых сложных проблем.

Спецификации Nvidia Tesla v100

2016: Nvidia Tesla P100
20 июня 2016 года компания Nvidia представила графический ускоритель для масштабируемых дата-центров — Nvidia Tesla P100. Решение для платформы ускоренных вычислений Nvidia Tesla содействует созданию класса серверов производительность которых на уровне нескольких сотен классических серверов на платформе CPU [1] .
Дата-центры — обширные сетевые инфраструктуры с многочисленными взаимосвязанными CPU-серверами — обрабатывают огромное количество транзакций, но их мощи недостаточно для обработки научных приложений и задач, связанных с искусственным интеллектом, когда требуются более эффективные, более скоростные серверные узлы. Ускоритель Tesla P100 на архитектуре Nvidia Pascal с пятью передовыми технологиями, согласно заявлению компании, обеспечивает высокую производительность и экономичность для самых ресурсоемких приложений.

Tesla P100 — первый ускоритель Nvidia со скоростью вычислений двойной и одинарной точности в 5 и 10 терафлопс соответственно. Tesla P100 на основе архитектуры Pascal повышает скорость обучения нейронных сетей в 12 раз по сравнению с решениями на основе архитектуры Nvidia Maxwell, заявили в компании Nvidia.
Процессор Pascal обладает 15,3 млрд транзисторов, построенных на базе 16 нм процесса FinFET. Он создан, чтобы обеспечить требуемую производительность и энергоэффективность для нагрузок с практически неограниченными вычислительными требованиями.
Представление глубокого изучения, (2016)
Nvidia анонсировала ряд обновлений в платформе разработки для GPU-вычислений, Nvidia SDK. В число обновлений входит Nvidia CUDA 8. Версия платформы параллельных вычислений Nvidia представляет разработчикам прямой доступ к новым возможностям Pascal, включая унифицированную память и NVLink. Кроме того, в актуальный релиз входит библиотека анализа графов nvGRAPH, которую можно использовать для расчета траекторий, информационной безопасности и анализа логистики, что включает в сферу применения GPU-ускоренных вычислений аналитику Big Data.
Графические ускорители Nvidia Tesla P100 на платформе Pascal появятся в составе системы обучения Nvidia DGX-1 в июне 2016 года. Ожидается, что процессор появится в составе серверов в начале 2017 года.
2014: Nvidia Tesla K80
В ноябре 2014 года NVIDIA представила решение для платформы ускоренных вычислений NVIDIA Tesla: двухпроцессорный графический ускоритель Tesla K80 – ускоритель, предназначенный для широкого спектра приложений, включая машинное обучение, анализ данных, научные и высокопроизводительные (HPC) расчеты.

Двухпроцессорный ускоритель Tesla K80 – флагман платформы ускоренных вычислений Tesla, платформы для анализа информации и ускорения научных исследований. Данная платформа объединяет GPU-ускорители, используемую модель параллельного программирования CUDA и обширную экосистему разработчиков приложений, поставщиков приложений и поставщиков решений для ЦОД.
Двухпроцессорный графический ускоритель Tesla K80 обладает почти в два раза более высокой производительностью и вдвое более широкой полосой пропускания памяти по сравнению с предшественником - Tesla K40. Новый ускоритель работает в десять раз быстрее самого мощного на сегодня CPU, обгоняя центральные процессоры и конкурирующие ускорители в сотнях вычислительно тяжелых приложений для анализа данных и научных расчетов.
Пользователи смогут раскрыть потенциал широкого спектра приложений благодаря новой версии технологии NVIDIA GPU Boost, которая позволяет динамически управлять частотами, повышая производительность каждого конкретного приложения.
Двухпроцессорный ускоритель Tesla K80 был разработан для вычислительных задач в таких областях, как астрофизика, геномика, квантовая химия, анализ данных и не только. Он также оптимизирован для продвинутых задач «глубокого обучения», одной из самых быстро развивающихся областей индустрии машинного обучения.
Tesla K80 превосходит все остальные ускорители по скорости вычислений—до 8.74 терафлопс для вычислений с плавающей точкой в одинарной точности и 2.91 терафлопс для двойной точности. Tesla K80 в десять раз быстрее, чем самые быстрые CPU в ведущих научных и инженерных приложениях, таких, как AMBER, GROMACS, Quantum Espresso и LSMS.
Ключевые возможности двухпроцессорного ускорителя Tesla K80:
- Два GPU на борту – вдвое более высокая скорость передачи данных в приложениях, использующих преимущества нескольких GPU.
- 24ГБ ультраскоростной памяти GDDR5 – 12ГБ памяти на GPU – вдвое больше, чем у Tesla K40 – позволяет обрабатывать вдвое большие наборы данных.
- Полоса пропускания 480ГБ/с – повышенная пропускная способность позволяет ученым обрабатывать петабайты информации вдвое быстрее по сравнению с Tesla K10. Оптимизировано для поисков источников энергии, обработки видео и изображений и анализа данных.
- 4992 параллельных ядра CUDA® – ускоряют приложения до 10 раз по сравнению с CPU.
- Динамическая технология NVIDIA GPU Boost – динамически меняет частоты GPU в зависимости от специфики приложений для максимальной производительности.
- Динамический параллелизм – позволяет потокам GPU динамически рождать новые потоки для быстрой и легкой обработки данных в адаптивных и динамических структурах.
Nvidia Tesla K20X
Производительность операций с двойной точностью

Ускорители Tesla GPU делают возможным совместное использование GPU и CPU в индивидуальном серверном узле или блейд-системе
Читайте также: