
Самая мощная видеокарта tesla
Обновлено: 02.07.2024
Для чего нужны видеокарты Quadro и Tesla, и почему они такие дорогие?
Наверное, странно видеть в продаже кусок текстолита и кремния за миллион рублей, в то время как игровая видеокарта, которая внутри почти такая же, как Quadro, стоит в 5-10 раз дешевле. Сегодня я расскажу для чего нужны видеокарты Quadro и Tesla, в чем их отличие от игровых видеокарт, а также можно ли на Quadro поиграть в игры.
Профессиональная линейка
Начнем с того, что Quadro, ровно как и Tesla - это профессиональные видеокарты. А чем, собственно, профессиональная видеокарта отличается от НЕпрофессиональной?
Как минимум - ̶ц̶е̶н̶о̶й̶ возлагаемыми задачами. Объясню очень просто: в играх на один кадр приходится относительно немного полигонов, но нужно просчитывать разные эффекты затенения/освещения в режиме реального времени со скоростью в 60 кадров в секунду.
А вот в CAD-программах все совсем иначе. Сцена там, часто, одна, и даже эффекты там есть не всегда, вот только состоит она из огромного количества полигонов (в десятки тысяч раз больше, чем в игровых сценах), которые надо просчитать с большой точностью.
При том в некоторых программах формы объектов описываются математическими функциями (для большей точности), и вот тут-то игровая видеокарта не пойдет ни в какое сравнение с Quadro. При этом у проф. карт есть фишки, которых нет у игровых видеокарт, вроде памяти с ECC.
Для этого и была создана Nvidia Quadro
Эти видеокарты базируются на тех же чипах, что и игровые видеокарты. Например, Quadro RTX 8000 базируется на том же ГП TU102, что и RTX 2080Ti. Даже больше скажу, эти видеокарты много где идентичны, однако различия все же есть.
- Больший объем памяти у Quadro
- Дополнительная гарантия с личным специалистом, к которому можно обратиться в случае возникновения проблем (все эти видеокарты производятся только одни вендором - PNY)
- Сертификация от разработчиков ПО
На последнем хотелось бы остановиться поподробнее. Дело в том, что при использовании профессиональных видеокарт, могут открыться некоторые технологии, которые недоступны при использовании игровых видеокарт той же серии (хотя они их поддерживают).
И вот однажды в какой-то программе ребята запустили недоступную технологию на игровой видеокарте, просто добавив ее в список поддерживаемых в файлах программы. Что за программа не помню, но суть вы уловили.
В общем, Quadro - это видеокарты со специальной сертификацией, которые как-то там оптимизированы под расчеты, но по сути - кроме драйверов и памяти отличий от игровых видеокарт имеют немного. Другое дело - видеокарты Tesla.
А для чего нужны Tesla?
Если просто посмотреть на эти видеокарты, то можно увидеть несколько странностей: видеовыходов нет, система охлаждения - пассивная (несмотря на огромное тепловыделение чипа), а главное - цена. Видеокарты Tesla могут спокойно стоить по миллиону рублей, и для всех это норма.
Но Tesla - не совсем видеокарта, а, скорее, графический ускоритель. То есть сама по себе она не умеет выводить картинку и предназначена для установки в помощь к какой-нибудь другой видеокарте (например, Quadro). Tesla можно обозвать и сопроцессором.
Помимо этого, Tesla имеет больше производительности на операциях двойной точности по сравнению, например, с видеокартой серии GeForce, которую тоже можно использовать как сопроцессор (естественно, сравниваем карты одного поколения). В разы больше памяти на борту у Tesla. Tesla может работать в режиме 24/7, что важно при выполнении длительных научных расчетов.
И там, раз уж на то пошло, целый ворох технологий, которые в рамках этой статьи я не распишу - она превратится в книгу. Так что уясним: Tesla - это вообще по сути не видеокарта, а графический ускоритель, который занимается расчетами и в профессиональных машинах, если и есть Tesla, то работает в тандеме с другой видеокартой.
Хотя есть сервера по каким-нибудь расчетам, так там можно увидеть и по 9-10 Tesla.
А можно ли поиграть на профессиональных видеокартах?
На Tesla это получится, скажем так, с некоторыми затруднениями, тогда как на Quadro - флаг в руки! Однако стоит учесть, что их производительность ниже, чем у игровых аналогов из-за сниженных частот.
NVIDIA Tesla K20X/K20: самые мощные серверные видеокарты на одном GPU


Обе новинки предлагаются в двухслотовом исполнении с пассивным охлаждением на печатных платах под шину PCI Express 3.0 x16.

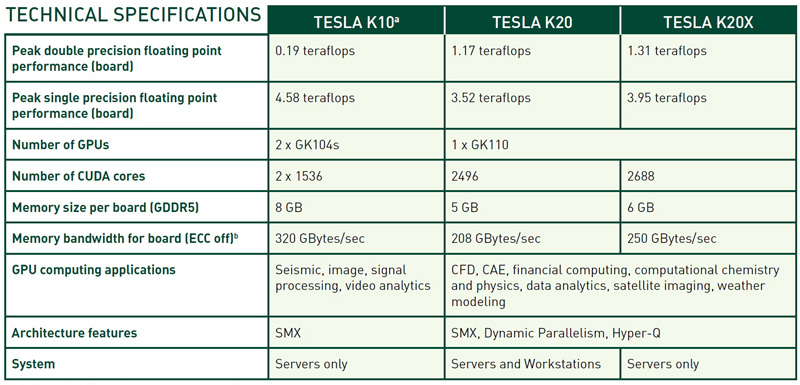
Флагман Tesla K20X с 2688 ядрами CUDA, как заявлено, обеспечивает самый высокий из возможных ныне уровень производительности для одного GPU, а именно 3,95 терафлопс в вычислениях с одинарной точностью и 1,31 терафлопс в вычислениях с двойной точностью. На его борту присутствует 6144 Мбайт памяти GDDR5 с 384-битным интерфейсом. Частота ядра/памяти равна 732/5200 МГц. Максимальная потребляемая мощность достигает 235 Вт.
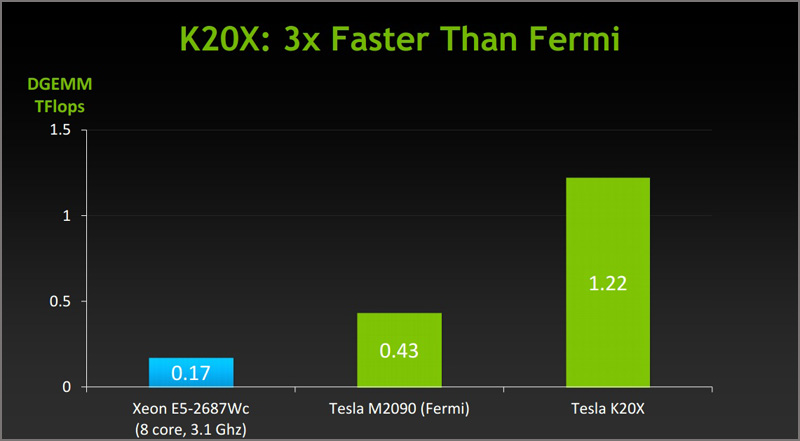
По словам разработчиков, 18688 ускорителей Tesla K20X легли в основу суперкомпьютера Titan, который, согласно новой редакции рейтинга TOP500, является на сегодняшний день самым мощным в мире. Данный суперкомпьютер расположен в Национальной Лаборатории Окриджа, штат Теннесси. Он стал новым лидером мирового рейтинга суперкомпьютеров с результатом в 17,59 петафлопс в бенчмарке LINPACK, сместив на этой позиции систему Sequoia из Ливерморской Национальной Лаборатории им. Лоуренса.

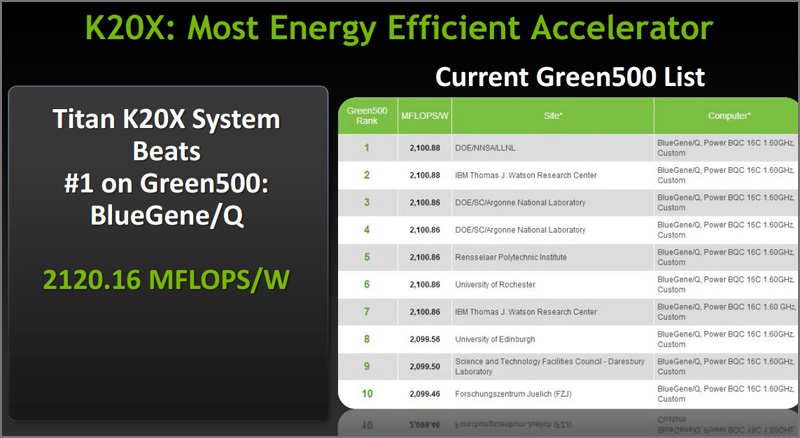
Попутно отмечается, что графический адаптер Tesla K20X отличается втрое меньшим энергопотреблением в сравнении с предыдущим поколением ускорителей NVIDIA и ещё больше увеличивает разрыв в производительности между GPU и CPU. Таким образом, суперкомпьютер Titan обеспечивает 2142,77 мегафлопс на Ватт и тем самым превосходит по энергоэффективности лидера последней версии списка самых экономичных суперкомпьютеров Green500.
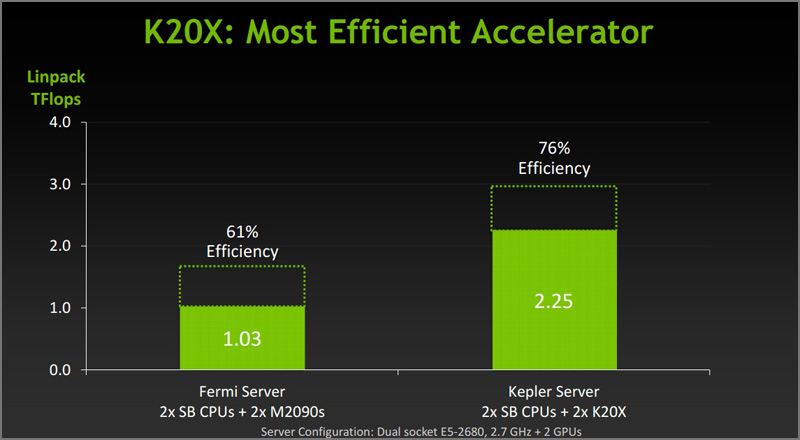
Создатели акцентируют внимание и на том, что модель Tesla K20X в сочетании с CPU поколения Sandy Bridge от Intel способна ускорять многие приложения более чем в 10 раз. Например, MATLAB (инженерия) – в 18,1 раза, Chroma (физика) – в 17,9 раз, SPECFEM3D (землеведение) – в 10,5 раз, AMBER (молекулярная динамика) – в 8,2 раза.
Напоследок сообщим, что описанные выше видеокарты уже поставляются и доступны в составе решений от ведущих производителей серверов, включая Appro, ASUS, Cray, Eurotech, Fujitsu, HP, IBM, Quanta Computer, SGI, Supermicro, T-Platforms и Tyan, а также у партнёров-реселлеров NVIDIA.
История потоковых мультипроцессоров Nvidia
Последние выходные я потратил на освоение программирования CUDA и SIMT. Это плодотворно проведённое время закончилось почти 700-кратным ускорением моего «рейтрейсера на визитке» [1] — с 101 секунд до 150 мс.
Такой приятный опыт стал хорошим предлогом для дальнейшего изучения темы и эволюции архитектуры Nvidia. Благодаря огромному объёму документации, опубликованному за долгие годы «зелёной» командой, мне удалось вернуться назад во времени и вкратце пройтись по удивительной эволюции её потоковых мультипроцессоров.
В этой статье мы рассмотрим:
Тупик
Вплоть до 2006 года архитектура GPU компании NVidia коррелировала с логическими этапами API рендеринга [2] . GeForce 7900 GTX, управлявшаяся кристаллом G71, состояла из трёх частей, занимавшихся обработкой вершин (8 блоков), генерацией фрагментов (24 блоков), и объединением фрагментов (16 блоков).
Кристалл G71. Обратите внимание на оптимизацию Z-Cull, отбрасывающую фрагмент, не прошедший бы Z-тест.
Эта корреляция заставила проектировщиков угадывать расположение «узких места» конвейера для правильной балансировки каждого из слоёв. С появлением в DirectX 10 ещё одного этапа — геометрического шейдера, инженеры Nvidia столкнулись со сложной задачей балансировки кристалла без знания того, насколько активно будет использоваться этот этап. Настало время для перемен.
Tesla
Nvidia решила проблему роста сложности при помощи «объединённой» архитектуры Tesla, выпущенной в 2006 году.
В кристалле G80 больше не было различий между слоями. Благодаря возможности выполнения вершинного, фрагментного и геометрического «ядра», потоковый мультипроцессор (Stream Multiprocessor, SM) заменил все существовавшие ранее блоки. Уравновешивание нагрузки выполнялось автоматически, благодаря замене выполняемого каждым SM «ядра» в зависимости от требований конвейера.
«Фактически, мы выбросили всю шейдерную архитектуру NV30/NV40 и с нуля создали новую, с новой общей архитектурой универсальных процессоров (SIMT), в которой также были введены новые методологии проектирования процессоров».
Джона Албен (интервью extremetech.com)
Больше не имеющие возможности выполнять инструкции SIMD «блоки шейдеров» превратились в «ядра», способные выполнять по одной целочисленной инструкции или по одной инструкции с float32 за такт. SM получает потоки в группах по 32 потока, называемых warp. В идеале все потоки одного warp выполняют одновременно одну и ту же инструкцию, только для разных данных (отсюда и название SIMT). Многопотоковый блок инструкций (Multi-threaded Instruction Unit, MT) занимается включением/отключением потоков в warp-е в случае, если их указатель инструкций (Instruction Pointer, IP) сходится/отклоняется.
Два блока SFU помогают выполнять сложные математические вычисления, например, обратный квадратный корень, sin, cos, exp и rcp. Эти блоки также способны выполнять по одной инструкции за такт, но поскольку их только два, скорость выполнения warp-а делится на четыре. Аппаратная поддержка float64 отсутствует, вычисления выполняются программно, что сильно влияет на скорость выполнения.
SM реализует свой максимальный потенциал, когда способен скрывать задержки памяти благодаря постоянному наличию диспетчеризируемых warp-ов, но также когда поток в warp-е не отклоняется (управляющая логика удерживает его на одном пути выполнения инструкций). Состояния потоков хранятся в 4-килобайтных файлах регистров (Register File, RF). Потоки, занимающие слишком большое пространство в стеке, снижают количество возможных потоков, которые могут выполняться одновременно, понижая при этом производительность.
Кристаллом-флагманом поколения Tesla был 90-нанометровый G80, представленный в GeForce 8800 GTX. Два SM объединены в кластер обработки текстур (Texture Processor Cluster, TPC) вместе с текстурным блоком (Texture Unit) и кешем Tex L1. Обещалось, что G80 с 8 TPC и 128 ядрами генерирует 345,6 гигафлопс [3] . Карта 8800 GTX была в своё время чрезвычайно популярна, она получила замечательные отзывы и полюбилась тем, кто мог себе её позволить. Она оказалась таким превосходным продуктом, что спустя тринадцать месяцев после выпуска оставалась одним из самых быстрых GPU на рынке.
G80, установленный в 8800 GTX. Render Output Units (ROP) занимаются выполнением сглаживания.
Вместе с Tesla компания Nvidia представила язык программирования C для Compute Unified Device Architecture (CUDA) — надмножество языка C99. Это понравилось энтузиастам GPGPU, приветствовавшим альтернативу обмана GPU при помощи текстур и шейдеров GLSL.
Хотя в этом разделе я в основном рассказываю о SM, это была только одна половина системы. В SM необходимо передавать инструкции и данные, хранящиеся в памяти GPU. Чтобы избежать простоев, GPU не пытаются минимизировать переходы в память при помощи больших кешей и прогнозирования, как это делают CPU. GPU пользуются задержкой, насыщая шину памяти для удовлетворения потребностей ввода-вывода тысяч потоков. Для этого кристалл (например, G80) реализует высокую пропускную способность памяти при помощи шести двусторонних шин памяти DRAM.
GPU пользуются задержками памяти, в то время как CPU скрывают их при помощи огромного кеша и логике прогнозирования.
Fermi
Tesla была рискованным ходом, оказавшимся очень успешным. Она была настолько успешной, что стала фундаментом для GPU компании NVidia на следующие два десятка лет.
«Хотя с тех пор мы, конечно же, внесли серьёзные архитектурные изменения (Fermi была серьёзным изменением архитектуры системы, а Maxwell стал ещё одним крупным изменением в проектировании процессоров), фундаментальная архитектура, представленная нами в G80, и сегодня осталась такой же [Pascal]».
Джона Албен (интервью extremetech.com)
В 2010 году Nvidia выпустила GF100, основанный на совершенно новой архитектуре Fermi. Внутренности её последнего чипа подробно описаны в технической документации Fermi [4] .
Модель выполнения по-прежнему основана на warp-ах из 32 потоков, диспетчеризируемых в SM. NVidia удалось удвоить/учетверить все показатели только благодаря 40-нанометровому техпроцессу. Благодаря двум массивам из 16 ядер CUDA, SM теперь мог одновременно диспетчеризировать два полу-warp-а (по 16 потоков). При том, что каждое ядро выполняло по одной инструкции за такт, SM по сути был способен исключать по одной инструкции warp за такт (в четыре раза больше, чем у SM архитектуры Tesla).
Количество SFU также увеличилось, однако не так сильно — мощность всего лишь удвоилась. Можно прийти к выводу, что инструкции такого типа использовались не очень активно.
Присутствует полуаппаратная поддержка float64, при которой комбинируются операции, выполняемые двумя ядрами CUDA. Благодаря 32-битном АЛУ (в Tesla оно было 24-битным) GF100 может выполнять целочисленное умножение за один такт, а из-за перехода от IEEE 754-1985 к IEEE 754-2008 имеет повышенную точность при работе с конвейером float32 при помощи Fused Multiply-Add (FMA) (более точного, чем используемое в Tesla MAD).
С точки зрения программирования, объединённая система памяти Fermi позволила дополнить CUDA C такими возможностями C++, как объект, виртуальные методы и исключения.
Благодаря тому, что текстурные блоки стали теперь SM, от концепции TPC отказались. Она была заменена кластерами Graphics Processor Clusters (GPC), имеющими по четыре SM. И последнее — SM теперь одарён Polymorph Engine, занимающимся получением вершин, преобразованием окна обзора и тесселяцией. Карта-флагман GeForce GTX 480 на основе GF100 рекламировалась, как содержащая 512 ядер и способная обеспечить 1 345 гигафлопс [5] .
GF100, установленный в GeForce GTX 480. Обратите внимание на шесть контроллеров памяти, обслуживающих GPC.
Kepler
В 2012 году Nvidia выпустила архитектуру Kepler, названную в честь астролога, наиболее известного открытием законов движения планет. Как обычно, взглянуть внутрь нам позволила техническая документация GK104 [6] .
В Kepler компания Nvidia значительно улучшила энергоэффективность кристалла, снизив тактовую частоту и объединив частоту ядер с частотой карты (ранее их частота различалась вдвое).
Такие изменения должны были привести к снижению производительности. Однако благодаря вдвое уменьшившемуся техпроцессу (28 нанометров) и замене аппаратного диспетчера на программный, Nvidia смогла не только разместить на чипе больше SM, но и улучшить их конструкцию.
Next Generation Streaming Multiprocessor (SMX) — это монстр, почти все показатели которого были удвоены или утроены.
Благодаря четырём диспетчерам warp-ов, способным на обработку целого warp-а за один такт (Fermi мог обрабатывать только половину warp-а), SMX теперь содержал 196 ядер. Каждый диспетчер имел двойную диспетчеризацию, позволявшую выполнять вторую инструкцию в warp-е, если она была независима от текущей исполняемой инструкции. Двойная диспетчеризация была не всегда возможна, потому что один столбец из 32 ядер был общим для двух операций диспетчеризации.
Такая схема усложнила логику диспетчеризации (к этому мы ещё вернёмся), но благодаря выполнению до шести инструкций warp-ов за такт SMX обеспечивал удвоенную производительность по сравнению с SM архитектуры Fermi.
Заявлялось, что флагманская NVIDIA GeForce GTX 680 с кристаллом GK104 и восемью SMX имеет 1536 ядер, достигающими 3 250 гигафлопс [7] . Элементы кристалла стали настолько запутанными, что мне пришлось убрать со схемы все подписи.
GK104, установленный в GeForce GTX 680.
Обратите внимание на полностью переделанные подсистемы памяти, работающие с захватывающей дух частотой 6 ГГц. Они позволили снизить количество контроллеров памяти с шести до четырёх.
Maxwell
В 2014 году Nvidia выпустила GPU десятого поколения под названием Maxwell. Как говорится в технической документации GM107 [8] , девизом первого поколения архитектуры стали «Максимальная энергоэффективность и чрезвычайная производительность на каждый потреблённый ватт». Карты позиционировались для «ограниченных в мощности сред, таких как ноутбуки и PC с малым форм-фактором (small form factor, SFF)».
Важнейшим решением стал отказ от структуры Kepler с количеством ядер CUDA в SM, не являющимся степенью двойки: некоторые ядра стали общими и вернулись в работе в режиме половины warp-ов. Впервые за всю историю архитектуры SMM имел меньше ядер, чем его предшественник: «всего» 128 ядер.
Согласование количества ядер и размера warp-ов улучшило сегментацию кристалла, что привело к экономии площади и энергии.
Один SMM 2014 года имел столько же ядер (128), сколько вся карта GTX 8800 в 2006 году.
Второе поколение Maxwell (описанное в технической документации GM200 [9] ) значительно повысило производительность, сохранив при этом энергоэффективность первого поколения.
Техпроцесс оставался на уровне 28 нанометров, поэтому инженеры Nvidia не могли для повышения производительности прибегнуть к простой миниатюризации. Однако уменьшение количества ядер SMM снизило их размер, благодаря чему на кристалле удалось разместить больше SMM. По сравнению с Kepler, второе поколение Maxwell удвоило количество SMM, при этом всего на 25% увеличив площадь кристалла.
В списке усовершенствований также можно найти упрощённую логику диспетчеризации, позволившую снизить количество избыточных повторных вычислений диспетчеризации и задержку вычислений, что обеспечило повышение оптимальности использования warp-ов. Также на 15% была увеличена частота памяти.
Изучение структурной схемы Maxwell GM200 уже начинает напрягать глаза. Но мы всё равно внимательно его исследуем. Флагманская карта NVIDIA GeForce GTX 980 Ti с кристаллом GM200 и 24 SMM обещала 3072 ядер и 6 060 гигафлопс [10] .
GM200, установленный в GeForce GTX 980 Ti.
Pascal
В 2016 году Nvidia представила Pascal. Техническая документация GP104 [11] оставляет ощущение дежавю, потому что Pascal SM выглядит точно так же, как Maxwell SMM. Отсутствие изменений SM не привело к стагнации производительности, потому что 16-нанометровый техпроцесс позволил разместить больше SM и снова удвоить количество гигафлопс.
Среди других серьёзных улучшений была система памяти, основанная на совершенно новой GDDR5X. 256-битный интерфейс памяти благодаря восьми контроллерам памяти обеспечивал скорости передачи в 10 гигафлопс, увеличив на 43% пропускную способность памяти и снизив время простоя warp-ов.
Флагман NVIDIA GeForce GTX 1080 Ti с кристаллом GP102 и 28 TSM обещал 3584 ядер и 11 340 гигафлопс [12] .
GP104, установленный в GeForce GTX 1080.
Turing
Выпуском в 2018 году Turing компания Nvidia произвела свой «крупнейший за десять лет архитектурный шаг вперёд» [13] . В «Turing SM» появились не только специализированные ядра Tensor с искусственным интеллектом, но и ядра для трассировки лучей (rautracing, RT). Такая фрагментированная структура напоминает мне многослойную архитектуру, существовавшую до Tesla, и это ещё раз доказывает, что история любит повторения.
Кроме новых ядер, в Turing появилось три важные особенности. Во-первых, ядро CUDA теперь стало суперскалярным, что позволяет параллельно выполнять инструкции с целыми числами и с числами с плавающей запятой. Если вы застали 1996 год, то это может напомнить вам об «инновационной» архитектуре Pentium компании Intel.
Во-вторых, новая подсистема памяти на GDDR6X, поддерживаемая 16 контроллерами, способна теперь обеспечивать 14 гигафлопс.
В-третьих, потоки теперь не имеют общих указателей инструкций (IP) в warp-е. Благодаря появившейся в Volta диспетчеризации Independent Thread Scheduling, каждый поток имеет собственный IP. В результате этого SM способны гибче настраивать диспетчеризацию потоков в warp-е без необходимости как можно более быстрого их схождения.
Флагманская карта NVIDIA GeForce GTX 2080 Ti с кристаллом TU102 и 68 TSM имеет 4352 и достигает 13 45 гигафлопс [14] . Я не стал рисовать структурную схему, потому что она выглядела бы как размытое зелёное пятно.
Что ждёт нас дальше
По слухам, следующая архитектура под кодовым названием Ampere будет объявлена в 2020 году. Так как Intel доказала на примере Ice Lake, что по-прежнему существует потенциал миниатюризации при помощи 7-нанометрового техпроцесса, почти нет сомнения в том, что Nvidia использует его для дальнейшего уменьшения SM и удвоения производительности.
Терафлопс/с для каждого кристалла/карты Nvidia (источник данных: techpowerup.com).
Интересно будет посмотреть, как Nvidia продолжит эволюцию идеи кристаллов, имеющих три типа ядер, выполняющих разные задачи. Увидим ли мы кристаллы, целиком состояние из Tensor-ядер или RT-ядер? Любопытно.
Графическая карта с 40 ГБ памяти и шиной с пропускной способностью 4,8 ТБ/с. Параметры ускорителя Nvidia Tesla A100 просто невероятны
Несмотря на то, что на сайте Nvidia ещё никакой информации ни о топовом GPU Ampere, ни об ускорители Tesla A100, в Сети уже появились подробные данные.
Напомним, сегодня мы уже узнали о том, что GPU, который некоторые источники называют не GA100, а A100, содержит невероятные 54 млрд транзисторов, а ускоритель Tesla A100 превосходит Tesla V100 в задачах ИИ и вычислениях с одинарной точностью (FP32) в 20 раз.
Теперь же появились подробности о конфигурации Tesla A100, хотя к этим данным есть вопросы. Начнём с того, что источник говорит о наличии у ускорителя 6912 ядер CUDA FP32 и 3456 ядер FP64, и совершенно неясно, что имеется в виду. Учитывая, что сам GPU относительно предшественника содержит более чем вдвое больше транзисторов, конечно, можно предположить, что в его конфигурацию входит более 10 000 ядер CUDA, но это вряд ли. К тому же другой источник считает, что сам GPU GA100 включает 8192 ядра CUDA, а в Tesla A100 просто активны не все. И это нормальная практика, однако и тут всё сходится не очень хорошо, ибо получается, что в топовом специализированном графическом ускорителе неактивно около 15% всех ядер, что было бы странно. К примеру, в Tesla V100 у графического процессора были отключены лишь 5% имеющихся у него ядер. Таким образом, этот вопрос пока остаётся открытым.
Также источник сообщает о наличии 432 тензорных ядер, 40 ГБ памяти HBM2e с 5120-разрядной шиной. Что интересно, при всей невероятной мощности TDP ускорителя составляет лишь 400 Вт. Да, в абсолютном выражении это очень много, но относительно характеристик, напротив, можно было бы ожидать большего.
Но это, конечно, не всё. Nvidia заявляет, что с GPU GA100 ей удалось добиться крупнейшего скачка производительности за все восемь поколений GPU, что стало возможным благодаря пяти технологическим прорывам.
Судя по всему, сюда входит новый семинанометровый техпроцесс TSMC, гигантское количество транзисторов, новые тензорые ядра третьего поколения, которые впервые поддерживают операции с плавающей запятой с одинарной и двойной точностью, межсетевое соединение NVLink с пропускной способностью в 4,8 ТБ/с (600 ГБ/с при подключении GPU-GPU), а также некая возможность «разделения» одного GPU на семь отдельных кластеров, каждый из которых якобы может выступать в роли отдельного графического процессора, но подробностей, к сожалению, нет.
Nvidia пока не называет цену ускорителя Tesla A100, но вот станция DGX A100 с восемью такими адаптерами обойдётся покупателям в 200 000 долларов.
Nvidia Tesla
GPU NVIDIA Tesla – это массивно параллельные ускорители, основанные на платформе параллельных вычислений NVIDIA CUDA. Графические процессоры Tesla специально разработаны для экономичных, высокопроизводительных вычислений, вычислительной науки и супервычислений, обеспечивая намного более высокую скорость работы широкого круга научных и коммерческих приложений по сравнению с системой на базе CPU.
CUDA – это платформа параллельных вычислений и модель программирования NVIDIA, которая обеспечивает значительное ускорение ресурсоемких расчетов с помощью графических процессоров. Модель программирования CUDA, загруженная более 1,7 миллиона раз и поддерживающая свыше 220 ведущих инженерных, научных и коммерческих приложений, является самым распространенным способом использования GPU ускорения при разработке приложений.
2017: Nvidia Tesla V100
GPU для дата-центров, предназначенный для ускорения искусственного интеллекта, HPC и графики. Основанный на самой современной архитектуре GPU [Nvidia Volta]], Tesla V100 предлагает в одном GPU производительность, равную 100 CPU, предоставляя ученым, исследователям и инженерам возможность находить решения для ранее нерешаемых проблем.
Тренировка алгоритмов искусственного интеллекта
Ученые берутся за все более сложные задачи, начиная от распознавания речи и обучения виртуальных ассистентов и заканчивая обнаружением дорожной разметки, и обучением беспилотных автомобилей вождению. Решение подобного рода задач требует обучения экспоненциально более сложных моделей нейронных сетей в сжатые сроки.
Оснащенный 43 тыс. ядер Tensor, Tesla V100 – это первый ускоритель, преодолевший барьер производительности в 100 тера-операций в секунду (TOPS) в задачах глубокого обучения. Второе поколение технологии NVIDIA NVLink™ соединяет несколько графических ускорителей V100, обеспечивая пропускную способность в 160 ГБ/с и позволяя создавать самые мощные вычислительные серверы. Модели, обучение которых занимало недели на системах предыдущего поколения, теперь можно натренировать всего за несколько дней. Благодаря такому серьезному сокращению времени, затрачиваемого на тренировку алгоритмов, искусственный интеллект поможет решить самовершенно новые проблемы.
Чтобы открыть нам доступ к актуальной информации, сервисам и продуктам, компании начали использовать искусственный интеллект. Однако удовлетворение потребностей пользователей – сложная задача. К примеру, по оценкам крупнейших компаний с гипермасштабируемой инфраструктурой, им придется вдвое увеличить быстродействие своих дата-центров, если каждый пользователь будет пользоваться их сервисами распознавания речи всего по три минуты в день.
Ускоритель Tesla V100 создан для обеспечения максимальной производительности в существующих сверхмасштабируемых дата-центрах. Один сервер, оснащенный Tesla V100 GPU и потребляющий 13 кВт энергии, обеспечивает в задачах инференса такую же производительность, как 30 CPU-серверов. Подобный скачок производительности и энергоэффективности способствует расширению масштабов применения сервисов с искусственным интеллектом.
высокопроизводительные вычисления
HPC – фундаментальная опора современной науки. Начиная от прогнозирования погоды и создания новых лекарств и заканчивая поиском источников энергии, ученые постоянно используют большие вычислительные системы для моделирования нашего мира и прогнозирования событий в нем. Искусственный интеллект расширяет возможности HPC, позволяя ученым анализировать большие объемы данных и добывая полезную информацию там, где одни симуляции не могут предоставить полную картину происходящего.
Графический ускоритель Tesla V100 создан, чтобы обеспечить слияние HPC и искусственного интеллекта. Это решение для HPC-систем, которое отлично проявит себя как в вычислениях для проведения симуляций, так и обработке данных для извечения из них полезной информации. Благодаря объединению в одной архитектуре ядер CUDA и Tensor, сервер, оснащенный графическими ускорителями Tesla V100, может заменить сотни традиционных CPU-серверов, выполняя традиционные задачи HPC и искусственного интеллекта. Теперь каждый ученый может позволить себе суперкомпьютер, который поможет в решении самых сложных проблем.

Спецификации Nvidia Tesla v100

2016: Nvidia Tesla P100
20 июня 2016 года компания Nvidia представила графический ускоритель для масштабируемых дата-центров — Nvidia Tesla P100. Решение для платформы ускоренных вычислений Nvidia Tesla содействует созданию класса серверов производительность которых на уровне нескольких сотен классических серверов на платформе CPU [1] .
Дата-центры — обширные сетевые инфраструктуры с многочисленными взаимосвязанными CPU-серверами — обрабатывают огромное количество транзакций, но их мощи недостаточно для обработки научных приложений и задач, связанных с искусственным интеллектом, когда требуются более эффективные, более скоростные серверные узлы. Ускоритель Tesla P100 на архитектуре Nvidia Pascal с пятью передовыми технологиями, согласно заявлению компании, обеспечивает высокую производительность и экономичность для самых ресурсоемких приложений.

Tesla P100 — первый ускоритель Nvidia со скоростью вычислений двойной и одинарной точности в 5 и 10 терафлопс соответственно. Tesla P100 на основе архитектуры Pascal повышает скорость обучения нейронных сетей в 12 раз по сравнению с решениями на основе архитектуры Nvidia Maxwell, заявили в компании Nvidia.
Процессор Pascal обладает 15,3 млрд транзисторов, построенных на базе 16 нм процесса FinFET. Он создан, чтобы обеспечить требуемую производительность и энергоэффективность для нагрузок с практически неограниченными вычислительными требованиями.
Представление глубокого изучения, (2016)
Nvidia анонсировала ряд обновлений в платформе разработки для GPU-вычислений, Nvidia SDK. В число обновлений входит Nvidia CUDA 8. Версия платформы параллельных вычислений Nvidia представляет разработчикам прямой доступ к новым возможностям Pascal, включая унифицированную память и NVLink. Кроме того, в актуальный релиз входит библиотека анализа графов nvGRAPH, которую можно использовать для расчета траекторий, информационной безопасности и анализа логистики, что включает в сферу применения GPU-ускоренных вычислений аналитику Big Data.
Графические ускорители Nvidia Tesla P100 на платформе Pascal появятся в составе системы обучения Nvidia DGX-1 в июне 2016 года. Ожидается, что процессор появится в составе серверов в начале 2017 года.
2014: Nvidia Tesla K80
В ноябре 2014 года NVIDIA представила решение для платформы ускоренных вычислений NVIDIA Tesla: двухпроцессорный графический ускоритель Tesla K80 – ускоритель, предназначенный для широкого спектра приложений, включая машинное обучение, анализ данных, научные и высокопроизводительные (HPC) расчеты.

Двухпроцессорный ускоритель Tesla K80 – флагман платформы ускоренных вычислений Tesla, платформы для анализа информации и ускорения научных исследований. Данная платформа объединяет GPU-ускорители, используемую модель параллельного программирования CUDA и обширную экосистему разработчиков приложений, поставщиков приложений и поставщиков решений для ЦОД.
Двухпроцессорный графический ускоритель Tesla K80 обладает почти в два раза более высокой производительностью и вдвое более широкой полосой пропускания памяти по сравнению с предшественником - Tesla K40. Новый ускоритель работает в десять раз быстрее самого мощного на сегодня CPU, обгоняя центральные процессоры и конкурирующие ускорители в сотнях вычислительно тяжелых приложений для анализа данных и научных расчетов.
Пользователи смогут раскрыть потенциал широкого спектра приложений благодаря новой версии технологии NVIDIA GPU Boost, которая позволяет динамически управлять частотами, повышая производительность каждого конкретного приложения.
Двухпроцессорный ускоритель Tesla K80 был разработан для вычислительных задач в таких областях, как астрофизика, геномика, квантовая химия, анализ данных и не только. Он также оптимизирован для продвинутых задач «глубокого обучения», одной из самых быстро развивающихся областей индустрии машинного обучения.
Tesla K80 превосходит все остальные ускорители по скорости вычислений—до 8.74 терафлопс для вычислений с плавающей точкой в одинарной точности и 2.91 терафлопс для двойной точности. Tesla K80 в десять раз быстрее, чем самые быстрые CPU в ведущих научных и инженерных приложениях, таких, как AMBER, GROMACS, Quantum Espresso и LSMS.
Ключевые возможности двухпроцессорного ускорителя Tesla K80:
- Два GPU на борту – вдвое более высокая скорость передачи данных в приложениях, использующих преимущества нескольких GPU.
- 24ГБ ультраскоростной памяти GDDR5 – 12ГБ памяти на GPU – вдвое больше, чем у Tesla K40 – позволяет обрабатывать вдвое большие наборы данных.
- Полоса пропускания 480ГБ/с – повышенная пропускная способность позволяет ученым обрабатывать петабайты информации вдвое быстрее по сравнению с Tesla K10. Оптимизировано для поисков источников энергии, обработки видео и изображений и анализа данных.
- 4992 параллельных ядра CUDA® – ускоряют приложения до 10 раз по сравнению с CPU.
- Динамическая технология NVIDIA GPU Boost – динамически меняет частоты GPU в зависимости от специфики приложений для максимальной производительности.
- Динамический параллелизм – позволяет потокам GPU динамически рождать новые потоки для быстрой и легкой обработки данных в адаптивных и динамических структурах.
Nvidia Tesla K20X
Производительность операций с двойной точностью

Ускорители Tesla GPU делают возможным совместное использование GPU и CPU в индивидуальном серверном узле или блейд-системе
Самая мощная видеокарта tesla

САМЫЕ БЫСТРЫЕ В МИРЕ УСКОРИТЕЛИ
Ускорение анализа больших данных и научных вычислений с помощью вычислительных карт NVIDIA Tesla - передовая технология области HPC. Благодаря продвинутым возможностям управления системой, ускоренной технологии коммуникации и поддержке известного ПО для управления инфраструктурой, вычислительные системы, построенные с использованием Tesla предоставляет профессионалам в области HPC инструменты для простого создания, тестирования и развертывания ускоренных приложений в центрах обработки данных.

Что это дает Вам?
- Производительность в операциях двойной точности до 2,91 терафлопс и производительность в операциях с одинарной точностью до 8,74 терафлопс на графическом ускорителе NVIDIA Tesla K80 от PNY.
- Максимальная производительность всех приложений благодаря технологии NVIDIA ® GPU Boost™.
- Повышенная производительность при работе с крупными наборами данных благодаря большому объему встроенной памяти (24 ГБ памяти на Tesla K80 GPU).
- Увеличенная скорость передачи данных для обеспечения доступности данных, когда они необходимы, благодаря высокой пропускной способности памяти (480 Гбит/с на Tesla K80 GPU).
- Высокая надежность работы с данными благодаря ECC защите для внутренней памяти GPU и внешней памяти GDDR5.
- До 2-х раз более высокая производительность приложений благодаря технологии внутреннего соединения NVIDIA NVLINK.
- Высокоскоростная двунаправленная передача данных благодаря двум движкам DMA, которыми оснащены графические ускорители Tesla.
- Ускоренная передача данных между узлами в сети и устройствах хранения данных, а также между GPU, использующими технологию NVIDA GPUDirect.
ВЫБЕРИТЕ GPU NVIDIA TESLA , КОТОРЫЙ ПОДХОДИТ ИМЕННО ВАМ
Графический ускоритель Tesla K40
Графический ускоритель NVIDIA Tesla K40 от PNY оснащен 12 ГБ памяти и обеспечивает пиковую производительность вычислений с двойной точностью в 1,43 терафлопс. Гибкое решение для приложений в области высокопроизводительных вычислений и анализа данных, графический ускоритель Tesla K40 без труда обеспечивает мощностью приложения в этой сфере.
Данный вычислитель доступен в исполнениях для графических станций (активное охлаждение) и для серверов (пассивное охлаждение).
Графический ускоритель Tesla K80
Карта с двумя GPU, которая объединяет в себе 24 ГБ памяти с молниеносной пропускной способностью и пиковой производительностью для вычислений двойной точности с плавающей точкой до 2,7 терафлопс благодаря технологии NVIDIA GPU Boost™. Tesla K80 GPU создан для выполнения самых требовательных к ресурсам вычислительных задач. Этот GPU идеально подходит для вычисления операций с двойной точностью, для которых требуется не только высокая производительность вычислений, но и высокая пропускная способность памяти.
Данный вычислитель доступен только в исполнении для серверов (пассивное охлаждение).

| Возможности | Tesla K80 1 | Tesla K40 |
| GPU | 2x Kepler GK210 | 1 Kepler GK110B |
| Пиковая производительность для вычислений двойной точности с плавающей точкой | 2.91 терафлопс (ускоренная частота) 1.87 терафлопс (базовая частота) | 1.66 терафлопс (ускоренная частота) 1.43 терафлопс (базовая частота) |
| Пиковая производительность для вычислений одинарной точности с плавающей точкой | 8.74 терафлопс (ускоренная частота) 5.6 терафлопс (базовая частота) | 5 терафлопс (ускоренная частота) 4.29 терафлопс (базовая частота) |
| Полоса пропускания памяти (без ECC) 2 | 480 Гбит/с (240 Гбит/с на GPU) | 288 Гбит/с |
| Размер памяти (GDDR5) | 24 ГБ (12GB на GPU) | 12 ГБ |
| Ядра CUDA | 4992 (2496 на GPU) | 2880 |
1 - Спецификации Tesla K80 указаны как для двух GPU.
2 - При включенной ECC памяти 6,25% памяти GPU используется для ECC. Например, при 6 ГБ общей памяти пользователь располагает 5.25 ГБ памяти.
Графические станции с вычислителем NVIDIA Tesla K40 от PNY
ARBYTE CADStation WS499
Самая производительная однопроцессорная модель. Хорошо подходит для работы с большими проектами, рендеринга, обработки видео, проведения инженерных расчетов малых и средних размерностей.
Чипсет: Intel iX99
Процессор: Intel® Intel Core™ i7-5xxx
Память: DDR4-2133, до 64 Гб
Видеоподсистема: профессиональная графическая карта Quadro
Вычислитель: NVIDIA Tesla K40 от PNY
Сконфигурировать и заказать
ARBYTE CADStation WS652
Двухпроцессорная станция. Используется для проведения инженерных расчетов средних и больших размерностей, рендеринга, обработки видео а также для работы с большими трехмерными проектами.
Чипсет: Intel С602
Процессоры: Intel® Xeon® серии E5
Память: DDR3-1600, ECC, reg., до 128 Гб
Видеоподсистема: профессиональная графическая карта Quadro
Вычислитель: NVUDIA Tesla K40 от PNY(до двух вычислителей)
Сконфигурировать и заказать
Серверные системы с вычислителем NVIDIA Tesla K80 от PNY
Эти системы позволяют установить большее количество вычислителей Tesla в единую систему под управлением одной операционной системы без необходимости создания кластерного комплекса. Используются вычислители с пассивным охлаждением. Доступны модели с установкой до 8 вычислителей Tesla в одну систему. Монтаж гибридных вычислителей предполагается в специальные шкафы или стойки.
NVIDIA Tesla K80 vs NVIDIA GeForce GTX 1080
Раздел общей информации в списке сравнения видеокарт содержит информацию о дате выпуска, типе, общем рейтинге и другие полезные данные для определения победителя между NVIDIA Tesla K80 и NVIDIA GeForce GTX 1080. Сравнение происходит по всем показателям из синтетических бенчмарков, которые определяют разные уровни игры и рабочих приложений.
Технические характеристики
Какая из видеокарт лучше в сравнении NVIDIA Tesla K80 против NVIDIA GeForce GTX 1080 в технологическом процессе изготовления, энергопотребления, а также наиболее важная часть, содержащаяся в рейтинге видеокарт.
Размеры, разъемы и совместимость
Давайте обсудим, какие размеры (длина, ширина, высота) у видеокарт NVIDIA Tesla K80 и NVIDIA GeForce GTX 1080.
Память (частота и разгон)
Память видеокарт играет роль как в играх, так и в графических приложениях. Чем выше стандарт (GDDR) тем лучше. Она напрямую влияет на скорость и эффективность обработки данных. В чем разница по типу, типу и турбо- частота, пропускной способности GDDR между NVIDIA Tesla K80 и NVIDIA GeForce GTX 1080:
Поддержка портов и дисплеев
Давайте подводим разницу в портах, оснащены видеокарты NVIDIA Tesla K80 и NVIDIA GeForce GTX 1080. Обратите внимание на количество портов и максимальное разрешение поддерживаемых мониторов.
Технологии
Посмотрим, в чем разница. Стоит отметить, что NVIDIA и AMD используют разные технологии.
API поддержки
Противостояние двух соперников NVIDIA Tesla K80 и NVIDIA GeForce GTX 1080 практически завершено. Аппаратная поддержка (API) не сильно влияет на общую производительность, она не учитывается в синтетических бенчмарках и других тестах производительности.
Игровая производительность
Выберите из списка имя, необходимое для определения игровой производительности NVIDIA Tesla Видеокарты K80 и NVIDIA GeForce GTX 1080. Результат показывает, насколько быстро игра будет работать и можно ли ее запустить на этом компьютере. Для тестирования используются различные разрешения мониторов - от низкого до 4K. Узнай, это NVIDIA Tesla K80 или NVIDIA GeForce GTX 1080 хороши для игр.
| низкий 1280x720 | мед. 1920x1080 | высокая 1920x1080 | ультра 1920x1080 | QHD 2560x1440 | 4K 3840x2160 |
| Horizon Zero Dawn (2020) | NVIDIA Tesla K80 | ||||
| NVIDIA GeForce GTX 1080 | |||||
| Death Stranding (2020) | NVIDIA Tesla K80 | ||||
| NVIDIA GeForce GTX 1080 | |||||
| F1 2020 (2020) | NVIDIA Tesla K80 | ||||
| NVIDIA GeForce GTX 1080 | |||||
| Gears Tactics (2020) | NVIDIA Tesla K80 | ||||
| NVIDIA GeForce GTX 1080 | 60 | 30.2 | |||
| Doom Eternal (2020) | NVIDIA Tesla K80 | ||||
| NVIDIA GeForce GTX 1080 |
| Legend | |
| 5 | Заикание - эта игра, скорее всего, будет заикаться и иметь низкую частоту кадров. На основе всех известных тестов с указанными графическими настройками ожидается, что средняя частота кадров упадет ниже 25 кадров в секунду. |
| Может заикаться - эта видеокарта не тестировалась специально в этой игре. На основе интерполированной информации от окружающих видеокарт с аналогичным уровнем производительности ожидаются заикания и низкая частота кадров. | |
| 30 | Свободно - на основе всех известных тестов с указанными графическими настройками, эта игра должна работать со скоростью 25 кадров в секунду или выше. |
| 40 | Свободно - на основе всех известных тестов с указанными графическими настройками, эта игра должна работать со скоростью 35 кадров в секунду или выше. |
| 60 | Свободно - на основе всех известных тестов с указанными графическими настройками, эта игра должна работать со скоростью 58 кадров в секунду или выше. |
| Может работать свободно - эта видеокарта явно не тестировалась в этой игре. На основе интерполированной информации от окружающих видеокарт с аналогичным уровнем производительности ожидается плавная частота кадров. | |
| ? | Неуверенно - у этой видеокарты возникли непредвиденные проблемы с производительностью во время тестирования этой игры. Более медленная карта может обеспечить лучшую и более стабильную частоту кадров, чем этот конкретный графический процессор, выполняющий ту же тестовую сцену. |
| Неуверенно - эта видеокарта явно не тестировалась в этой игре, и невозможно сделать надежную интерполяцию на основе характеристик соседних карт того же класса или семейства. | |
| Значение в полях отображает среднюю частоту кадров всех значений в базе данных. Move наведите курсор на значение, чтобы увидеть отдельные результаты. | |
Преимущества NVIDIA Tesla K80
Больше максимальный объем оперативной памяти (12 ГБ против 8 ГБ)
Преимущества NVIDIA GeForce GTX 1080
68.18% еaster в синтетических тестах
Больше конвейеров (2560 против 2496)
Более тонкое производствоturing техпроцесс (16 нм против 28 нм)
Меньше энергопотребление (180 Вт против 300 Вт)
Больше пропускная способность памяти (320 ГБ / с против 240.6 ГБ / с)
Итак, NVIDIA Tesla K80 или NVIDIA GeForce GTX 1080?
Судя по результатам синтетического и игрового тестов, мы рекомендуем NVIDIA GeForce GTX 1080.
NVIDIA представит 7-нм GPU Ampere в рамках конференции GTC 2020 в марте
Согласно неофициальной информации, NVIDIA представит 7-нм микроархитектуру Ampere и первый графический ускоритель на ее основе в рамках конференции GTC 2020 (22 – 26 марта 2020 года). В прошлом NVIDIA неоднократно использовала ее для дебюта своих новых микроархитектур.
Правда, GTC концентрируется на вопросах ускорения глубинного обучения, искусственного интеллекта, вычислительных задач в дата-центрах и суперкомпьютерах, поэтому речь идет не о массовых игровых видеокартах, а о графическом ускорителе для HPC и AI вроде NVIDIA Tesla V100.

А вот для анонса обычных игровых видеокарт NVIDIA может выбрать выставку Computex 2020. Тем более что их полноценный релиз на рынке ожидается лишь во второй половине 2020 года. Пока мы очень мало знаем об Ampere. Ходят слухи, что производством GPU займется компания Samsung с использованием технологии 7-нм EUV. Ожидаем повышенной производительности и энергоэффективности по сравнению с 12-нм Turing.
Ускоритель NVIDIA Tesla T4 для дата-центров и сервисов ИИ
NVIDIA Tesla T4 построена на базе особой версии GPU NVIDIA TU104, который также находится в основе массовой видеокарты NVIDIA GeForce RTX 2080. Но если последняя предоставляет 2944 CUDA-ядер при энергопотреблении 215 – 225 Вт, то NVIDIA Tesla T4 может похвастать 2560 CUDA-ядрами и 320 тензорными ядрами Turing при энергопотреблении всего 75 Вт. Вычислительная мощность новинки следующая:
- FP32 – 8,1 TFLOPS
- FP16 – 65 TFLOPS
- INT8 – 130 TOPS
- INT4 – 260 TOPS
В паре с GPU работает 16 ГБ GDDR6-памяти с пропускной способностью более 320 ГБ/с. А для подключения используется внутренний интерфейс PCI Express 3.0 x16. Ускоритель NVIDIA Tesla T4 заинтересовал ключевых игроков, поэтому вскоре он появится в решениях от Cisco, Dell, Fujitsu, HPC, IBM, Oracle, Supermicro и других.
Intel может представить дискретную видеокарту уже в рамках CES 2019

Сообщается, что Intel работает над созданием дискретной видеокарты уже в течение двух лет. Поэтому Раджа Кодури (Raj Koduri), который перешел в Intel в конце прошлого года и возглавил соответствующее подразделение, не занимался разработкой с нуля, а помогает довести до финальной стадии уже имеющиеся наработки.
По информации источников, приоритетом для Intel являются профессиональные видеоускорители, которые можно использовать, например, для обучения нейронных сетей (AI). Поэтому первыми будут представлены конкуренты для серий NVIDIA Tesla и NVIDIA Quadro. А уже затем дизайн может быть упрощен для реализации массовых пользовательских видеокарт, конкурентов для серий NVIDIA GeForce и AMD Radeon.
В HWiNFO замечены предстоящие CPU и GPU от AMD и не только
По устоявшейся традиции, в очередном обновлении утилиты для диагностики ПК HWiNFO засветились CPU и GPU от AMD следующего поколения, что может намекать на скорый их анонс. В программе замечена поддержка графических процессоров линейки AMD Navi, платформы AMD Pinnacle Ridge, материнских плат 400-й серии, а также серверного процессора AMD Starship, платформы AMD Matisse и GPU Radeon RX Vega M.

Кроме продукции от AMD, в утилите появилось и упоминание о поддержке серверных процессоров линейки Intel Ice Lake-SP, а также профессиональных графических ускорителей линейки NVIDIA Quadro V100, которые, скорей всего, будут основаны на прошлогоднем GPU NVIDIA Tesla V100.
Суперкомпьютер NVIDIA SaturnV с GPU NVIDIA Volta
Компания NVIDIA анонсировала выпуск обновленного суперкомпьютера NVIDIA SaturnV, который не только войдет в десятку самых мощных суперкомпьютеров для искусственного интеллекта, но и станет самым энергоэффективным из них.

Главной же его особенностью станет наличие 660 модулей NVIDIA DGX-1, каждый из которых обладает восемью ускорителями NVIDIA Tesla V100. Таким образом, общее количество графических ядер NVIDIA Volta достигнет 5280. Это позволит достичь пиковой вычислительной способности FP64 на уровне 40 petaFLOPS (40 000 TFLOPS) и FP16 до 660 petaFLOPS.

Однако NVIDIA SaturnV будет не единственным суперкомпьютером с использованием NVIDIA Volta. Ранее было анонсировано подобное устройство под названием Summit, которое является совместной разработкой компаний NVIDIA и IBM. Также в Японии разработан суперкомпьютер ABCI, который получил 4352 GPU NVIDIA Volta.

Компания NVIDIA заявляет, что обновленный суперкомпьютер NVIDIA SaturnV будет использоваться для разработки и обучения искусственного интеллекта, который будет применяться в беспилотных автомобилях.
Драйвера версии NVIDIA GeForce 384 добавляют поддержку DirectX 12 видеокартам NVIDIA GeForce 400-й и 500-й серии

Драйверы NVIDIA GeForce 384-й версии позволят запускать на указанных выше видеокартах игры и приложения с функциями Direct3D 12.0, а также добавляют поддержку архитектуры WDDM 2.2 в среде ОС Windows 10 Creators Update (версия 1703).
Более подробную информацию можно узнать на форуме Guru3D.com.
Анонсирована версия графического ускорителя NVIDIA Tesla V100 с интерфейсом PCI Express 3.0
Чуть более месяца назад компания NVIDIA представила графический ускоритель NVIDIA Tesla V100, который положил начало распространению микроархитектуры NVIDIA Volta. Он предназначается для использования в системах глубинного обучения и научных исследований, а также оснащается интерфейсом NVLink.
Теперь NVIDIA представила вариацию этого видеоадаптера в виде классической видеокарты с использованием интерфейса PCI Express 3.0. Графическое ядро NVIDIA GV100 обладает 5120 CUDA-ядрами FP32, 2560 FP64 и 640 Tensor Core, а динамическая частота его работы достигает 1370 МГц, что несколько ниже 1455 МГц у ранее представленной версии видеоадаптера. В связи с этим пиковая вычислительная мощность FP32 и FP64 уменьшилась с 15 / 7,5 TFLOPS до 14 / 7 TFLOPS соответственно, а уровень TDP данной модификации NVIDIA Tesla V100 снизился с 300 до 250 Вт. Видеобуфер представлен теми же 16 ГБ HBM2-памяти с пропускной способностью 900 ГБ/с.
Новинка рассчитана на использование в серверах глубинного обучения, научных исследований и анализа. Она появится на рынке до конца текущего года.
Следующая линейка видеокарт NVIDIA GeForce не будет использовать память HBM2?
Новая микроархитектура NVIDIA Volta дебютировала в мае путем анонса графического ускорителя NVIDIA Tesla V100. Он построен на основе самого большого GPU в арсенале компании – NVIDIA GV100. Его площадь составляет 815 мм 2 , а общее количество транзисторов превысило 21 млрд. Он разработан для применения в системах искусственного интеллекта и глубинного обучения.
Конечно, представители следующего поколения массовых пользовательских видеокарт NVIDIA GeForce не получат этот GPU, поскольку это было бы слишком рискованно и дорого. Вместо него ожидаем увидеть технологический потенциал графических процессоров NVIDIA GV102, GV104, GV106 и GV108 (если NVIDIA cохранит привычную схему наименований).

Также проверенный источник, близкий к NVIDIA, заявляет, что новые видеокарты NVIDIA GeForce не смогут похвастать наличием памяти HBM2, поскольку этот тип памяти будет слишком дорогим, что повлияет на конечную стоимость продукта. Поэтому NVIDIA будет использовать возможности GDDR5X-памяти, скоростные показатели которой уже могут достигать уровня 16 Гбит/с. Не исключена также интеграция стандарта GDDR6, однако пока уверенно говорить об этом еще рано.
Вполне возможно, что NVIDIA также заняла выжидательную позицию в связи со скорым релизом графических адаптеров AMD Radeon Vega с использованием HBM2-видеопамяти и реакцией рынка на это событие.
Читайте также: